Annotations
In addition to the basic OCR functionality, Mistral Document AI API adds the annotations functionality, which allows you to extract information in a structured json-format that you provide.
Before You Start
What can you do with Annotations?
Specifically, it offers two types of annotations:
bbox_annotation: gives you the annotation of the bboxes extracted by the OCR model (charts/ figures etc) based on user requirement and provided bbox/image annotation format. The user may ask to describe/caption the figure for instance.document_annotation: returns the annotation of the entire document based on the provided document annotation format.
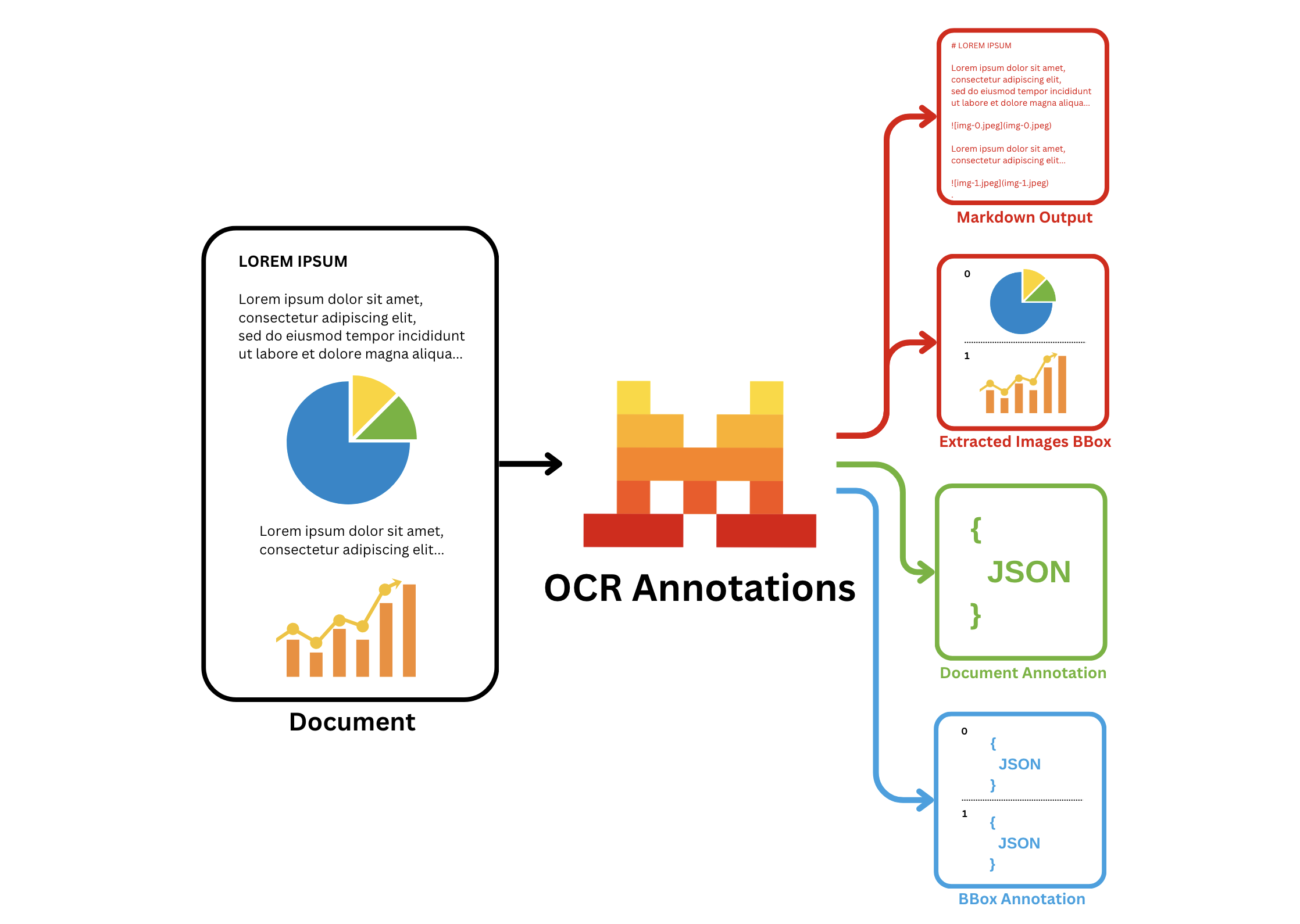
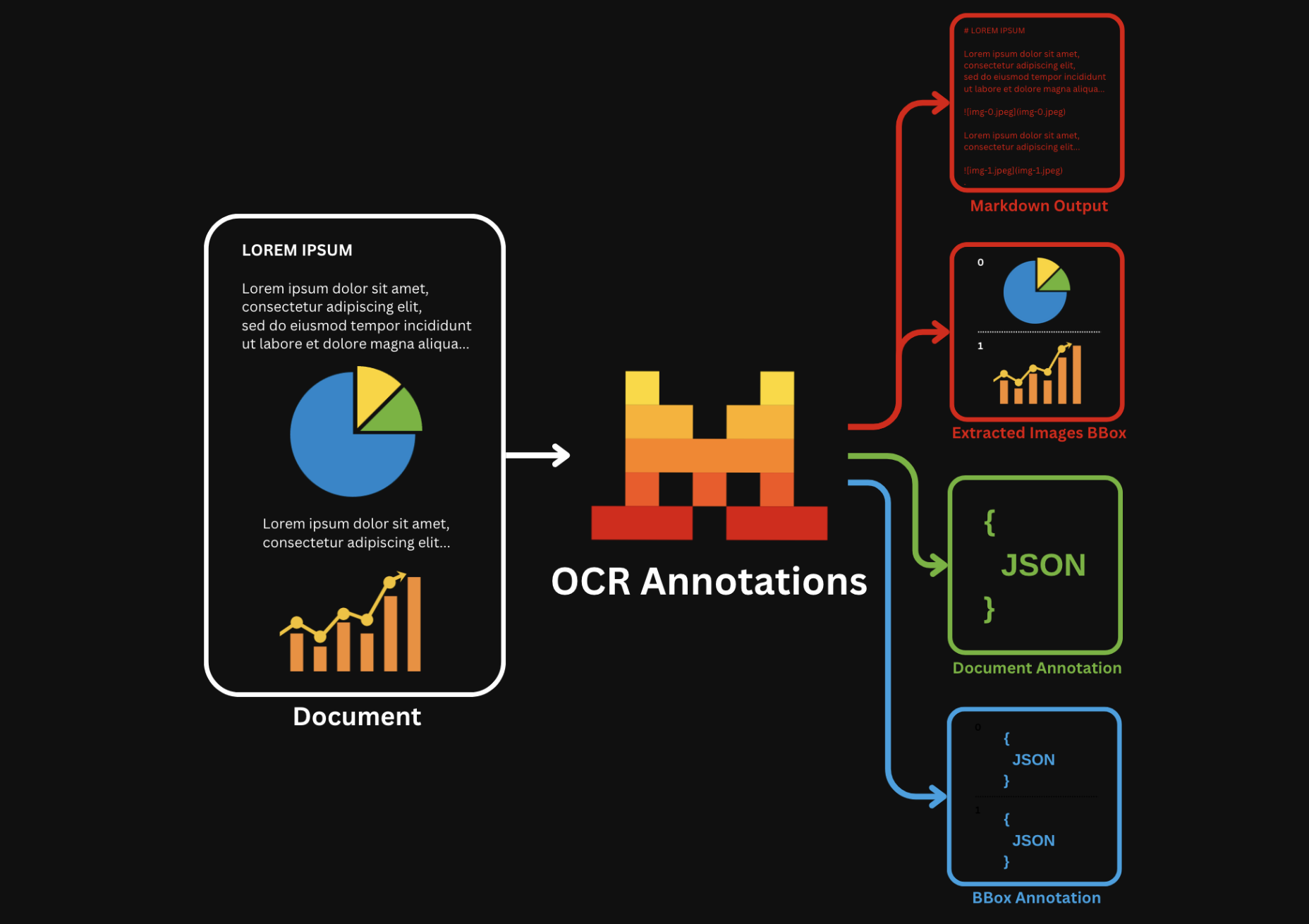
Key Capabilities
- Labeling and annotating data
- Extraction and structuring of specific information from documents into a predefined JSON format
- Automation of data extraction to reduce manual entry and errors
- Efficient handling of large document volumes for enterprise-level applications
Common Use Cases
- Parsing of forms, classification of documents, and processing of images, including text, charts, and signatures
- Conversion of charts to tables, extraction of fine print from figures, or definition of custom image types
- Capture of receipt data, including merchant names and transaction amounts, for expense management.
- Extraction of key information like vendor details and amounts from invoices for automated accounting.
- Extraction of key clauses and terms from contracts for easier review and management
How it Works
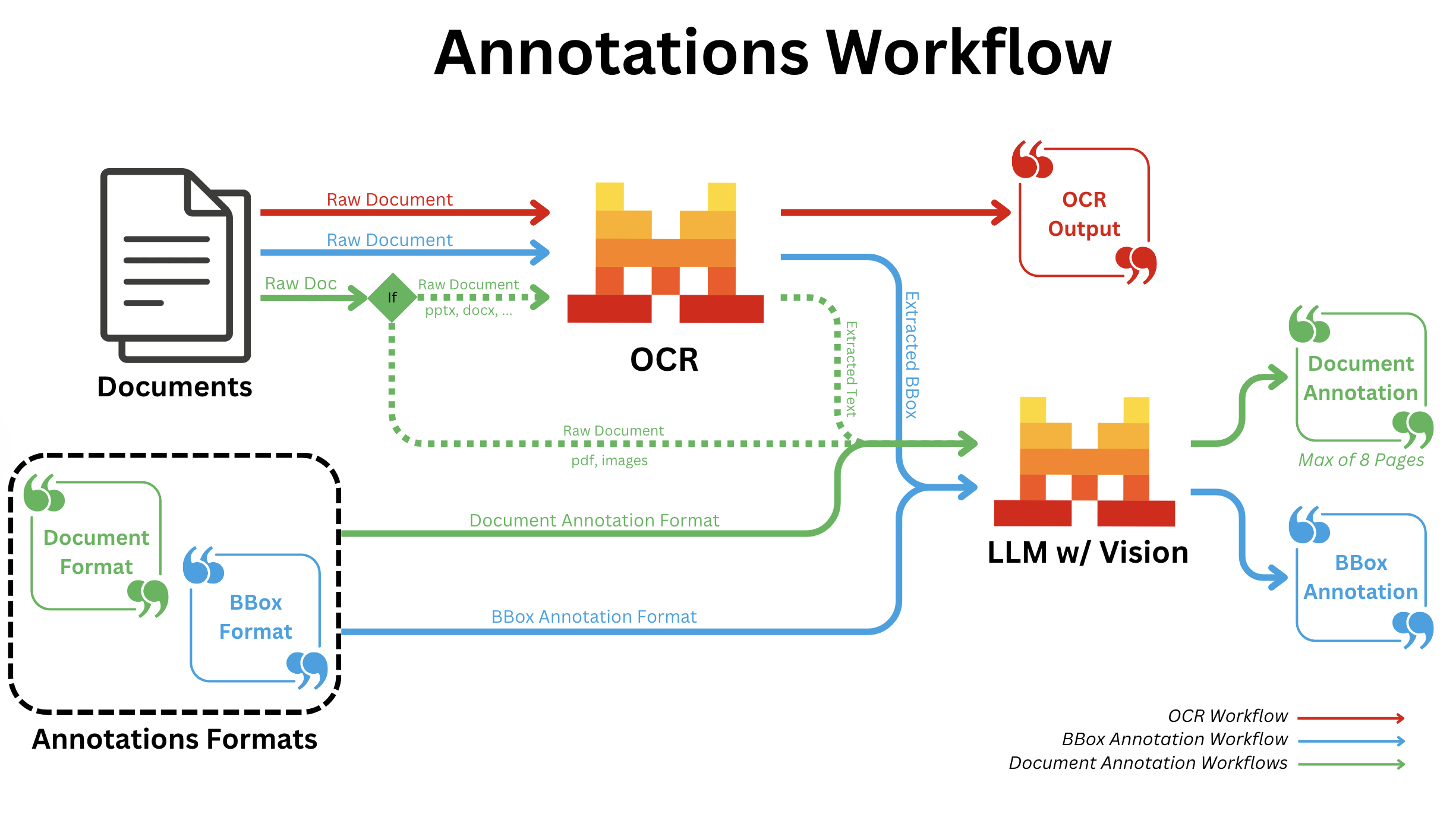
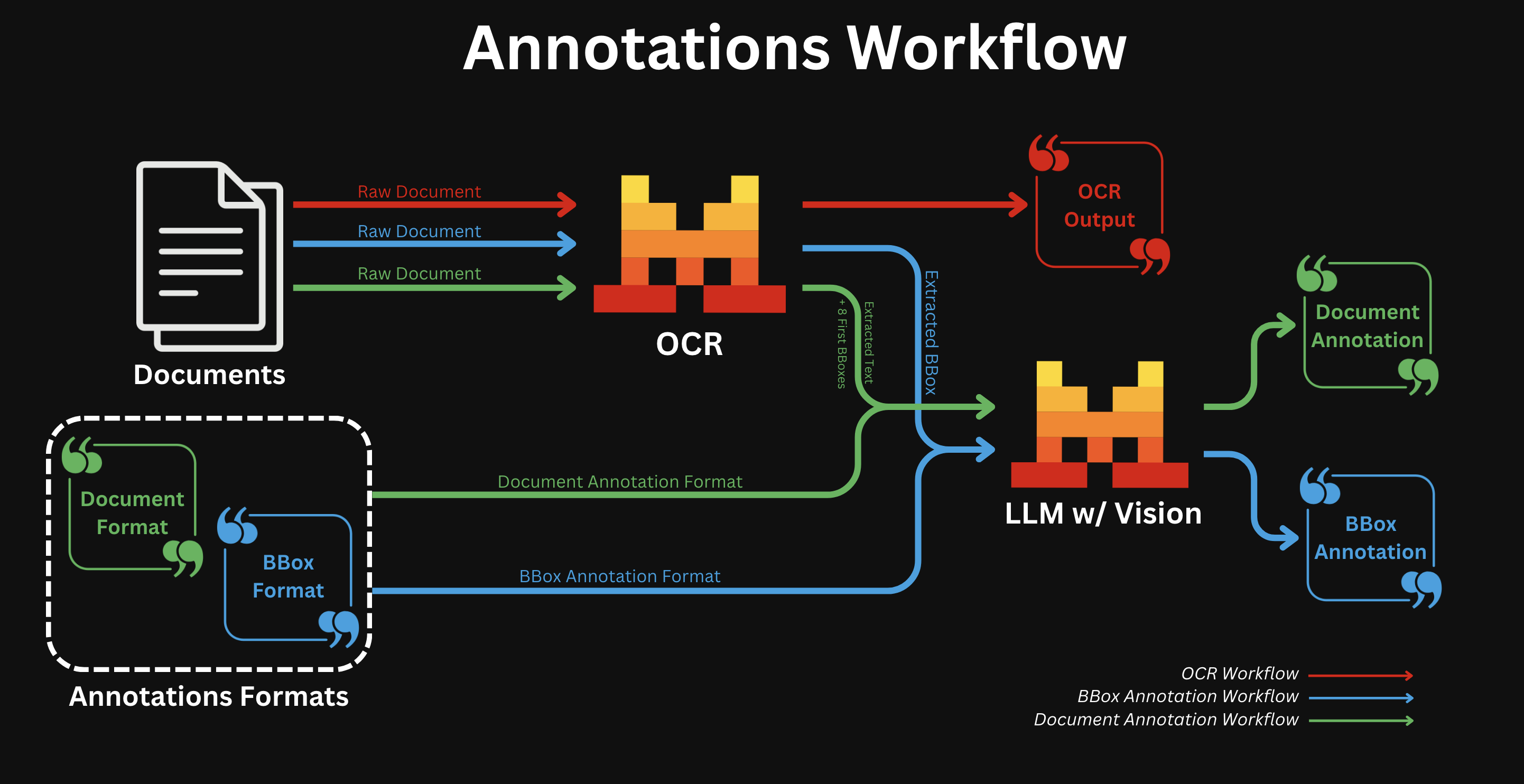
BBOX Annotations
- All document types:
- After regular OCR is finished; we call a Vision capable LLM for all bboxes individually with the provided annotation format.
Document Annotation
- All document types:
- We run OCR and send the output text in Markdown, along with the first eight extracted image bounding boxes, to a vision-capable LMM, together with the provided annotation format.
Accepted Formats
You can use our API with the following document formats:
- OCR with pdf
- OCR with image: even from low-quality or handwritten sources.
- scans, DOCX, PPTX...
In the code snippets below, we will consider the OCR with pdf format.
Usage
How to Annotate
As previously mentionned, you can either:
- Use the
bbox_annotationfunctionality, allowing you to extract information from the bboxes of the document. - Use the
document_annotationfunctionality, allowing you to extract information from the entire document.- Optionally, we also provide the ability to add a
document_annotation_prompt, a high level general prompt to guide and instruct on how to annotate the document.
- Optionally, we also provide the ability to add a
- Use both functionalities at the same time.
Here is an example of how to use our BBox Annotation functionalities.
Define the Data Model
First, define the response formats for BBox Annotation, using either Pydantic or Zod schemas for our SDKs, or a JSON schema for a curl API call.
Pydantic/Zod/JSON schemas accept nested objects, arrays, enums, etc...
from pydantic import BaseModel
# BBOX Annotation response formats
class Image(BaseModel):
image_type: str
short_description: str
summary: strYou can also provide a description for each entry, the description will be used as detailed information and instructions during the annotation; for example:
from pydantic import BaseModel, Field
# BBOX Annotation response formats
class Image(BaseModel):
image_type: str = Field(..., description="The type of the image.")
short_description: str = Field(..., description="A description in english describing the image.")
summary: str = Field(..., description="Summarize the image.")Start Request
Next, make a request and ensure the response adheres to the defined structures using bbox_annotation_format set to the corresponding schemas:
import os
from mistralai.client import Mistral, DocumentURLChunk, ImageURLChunk, ResponseFormat
from mistralai.extra import response_format_from_pydantic_model
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
response = client.ocr.process(
model="mistral-ocr-latest",
document=DocumentURLChunk(
document_url="https://arxiv.org/pdf/2410.07073"
),
bbox_annotation_format=response_format_from_pydantic_model(Image),
include_image_base64=True
)BBox Annotation Example Output
The BBox Annotation feature allows to extract data and annotate images that were extracted from the original document, below you have one of the images of a document extracted by our OCR Processor.
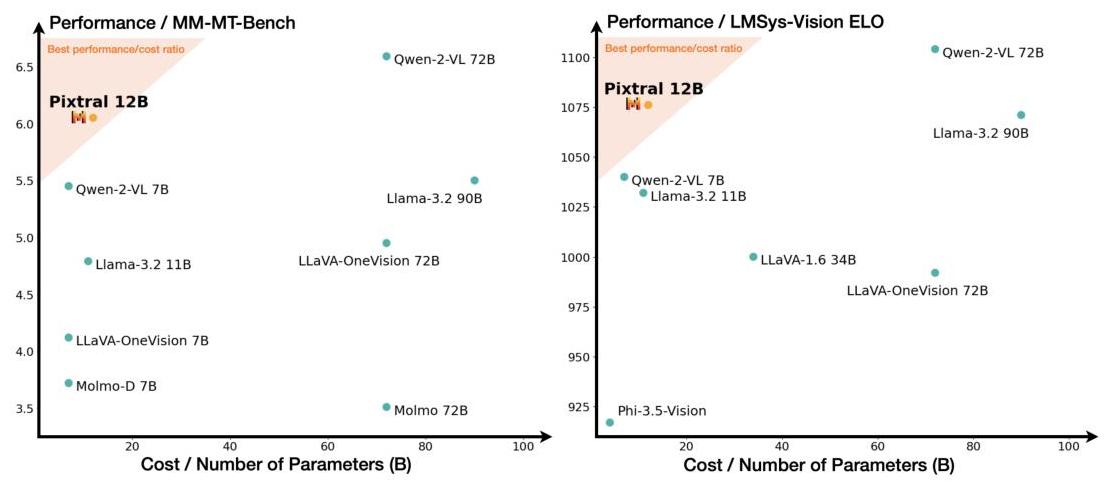
The Image extracted is provided in a base64 encoded format.
{
"image_base64": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGB{LONG_MIDDLE_SEQUENCE}KKACiiigAooooAKKKKACiiigD//2Q==..."
}And you can annotate the image with the model schema you want, below you have an example output.
{
"image_type": "scatter plot",
"short_description": "Comparison of different models based on performance and cost.",
"summary": "The image consists of two scatter plots comparing various models on two different performance metrics against their cost or number of parameters. The left plot shows performance on the MM-MT-Bench, while the right plot shows performance on the LMSys-Vision ELO. Each point represents a different model, with the x-axis indicating the cost or number of parameters in billions (B) and the y-axis indicating the performance score. The shaded region in both plots highlights the best performance/cost ratio, with Pixtral 12B positioned within this region in both plots, suggesting it offers a strong balance of performance and cost efficiency. Other models like Qwen-2-VL 72B and Qwen-2-VL 7B also show high performance but at varying costs."
}Cookbooks
For more information and guides on how to make use of OCR, we have the following cookbooks: