Reasoning
Reasoning is the next step of CoT (Chain of Thought), naturally used to describe the logical steps generated by the model before reaching a conclusion. Reasoning strengthens this characteristic by going through training steps that encourage the model to generate chains of thought freely before producing the final answer. This allows models to explore the problem more profoundly and ultimately reach a better solution to the best of their ability by using extra compute time to generate more tokens and improve the answer—also described as Test Time Computation.
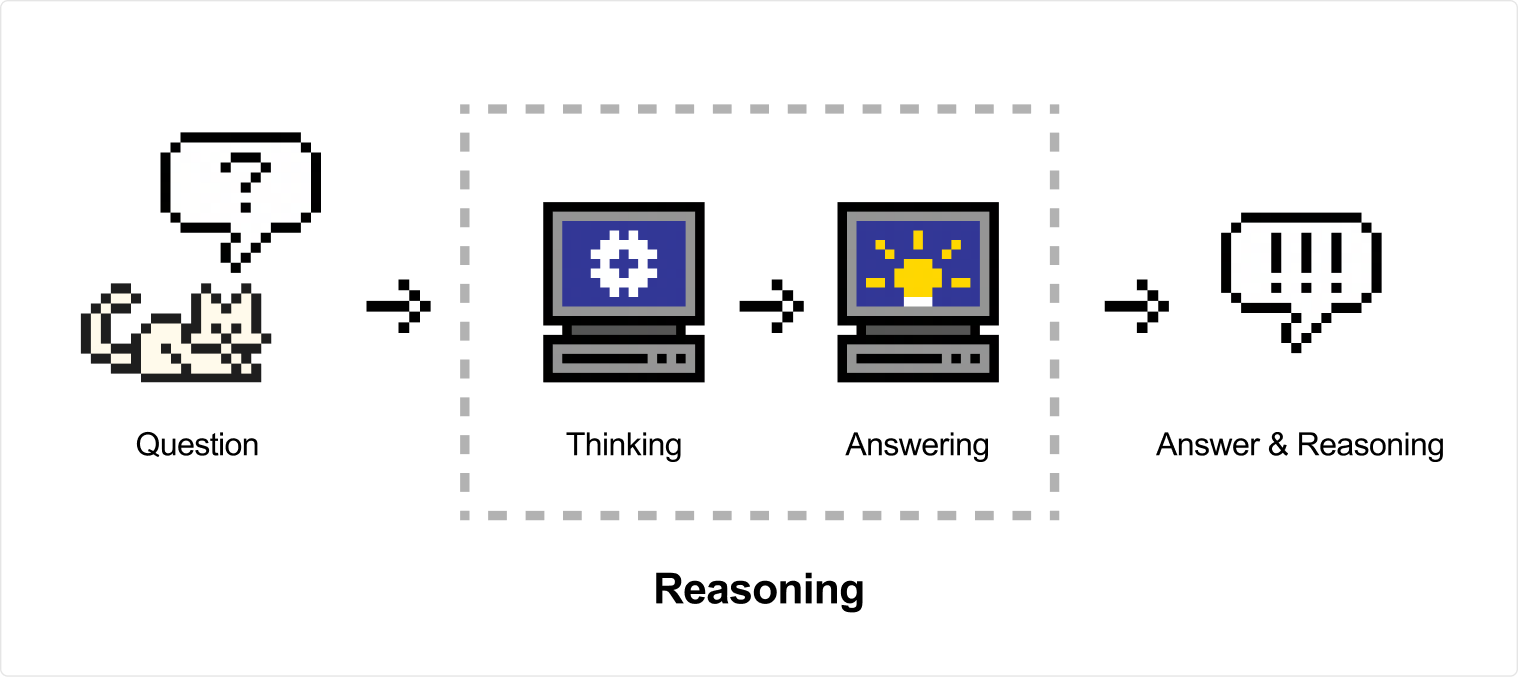
They excel at complex use cases like math and coding tasks, but can be used in a wide range of scenarios to solve diverse problems. The output of reasoning models includes a reasoning chunk with the model's thinking traces, followed by the final answer.
Mistral offers two approaches to reasoning:
-
Adjustable — Available on
mistral-small-latestandmistral-medium-3-5via thereasoning_effortparameter. Enables the model to think to varying degrees. -
Native — Available on
magistral-small-latestandmagistral-medium-latest. These models always generate reasoning traces and are purpose-built for deep reasoning tasks.