Vision
Vision capabilities enable models to analyze images and provide insights based on visual content in addition to text. This multimodal approach opens up new possibilities for applications that require both textual and visual understanding.
We provide a variety of models with vision capabilities, all available via the Chat Completions API.
For document parsing, OCR, and data extraction, see Document AI.
Before You Start
Recommended Models with Vision Capabilities
- Mistral Large 3 via
mistral-large-2512 - Mistral Medium 3.1 via
mistral-medium-2508 - Mistral Small 3.2 via
mistral-small-2506 - Ministral 3:
- Ministral 3 14B via
ministral-14b-2512 - Ministral 3 8B via
ministral-8b-2512 - Ministral 3 3B via
ministral-3b-2512
- Ministral 3 14B via
Sending an Image
Use Vision Models
There are two ways to send an image to the Chat Completions API, either by passing a URL or by passing a base64 encoded image.
Before continuing, we recommend reading the Chat Completions documentation to learn more about the chat completions API and how to use it before proceeding.
If the image is hosted online, you can simply provide the publicaly accessible URL of the image in the request. This method is straightforward and does not require any encoding.
import os
from mistralai.client import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "mistral-small-latest"
client = Mistral(api_key=api_key)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's in this image?"
},
{
"type": "image_url",
"image_url": "https://docs.mistral.ai/img/eiffel-tower-paris.jpg"
}
]
}
]
chat_response = client.chat.complete(
model=model,
messages=messages
)Use cases
Below you can find a few examples of use cases leveraging our models vision, from understanding graphs to extract data, the use cases are diverse.
These are simple examples you can use as inspiration to build your own use cases. For OCR and structured outputs, see Document AI.
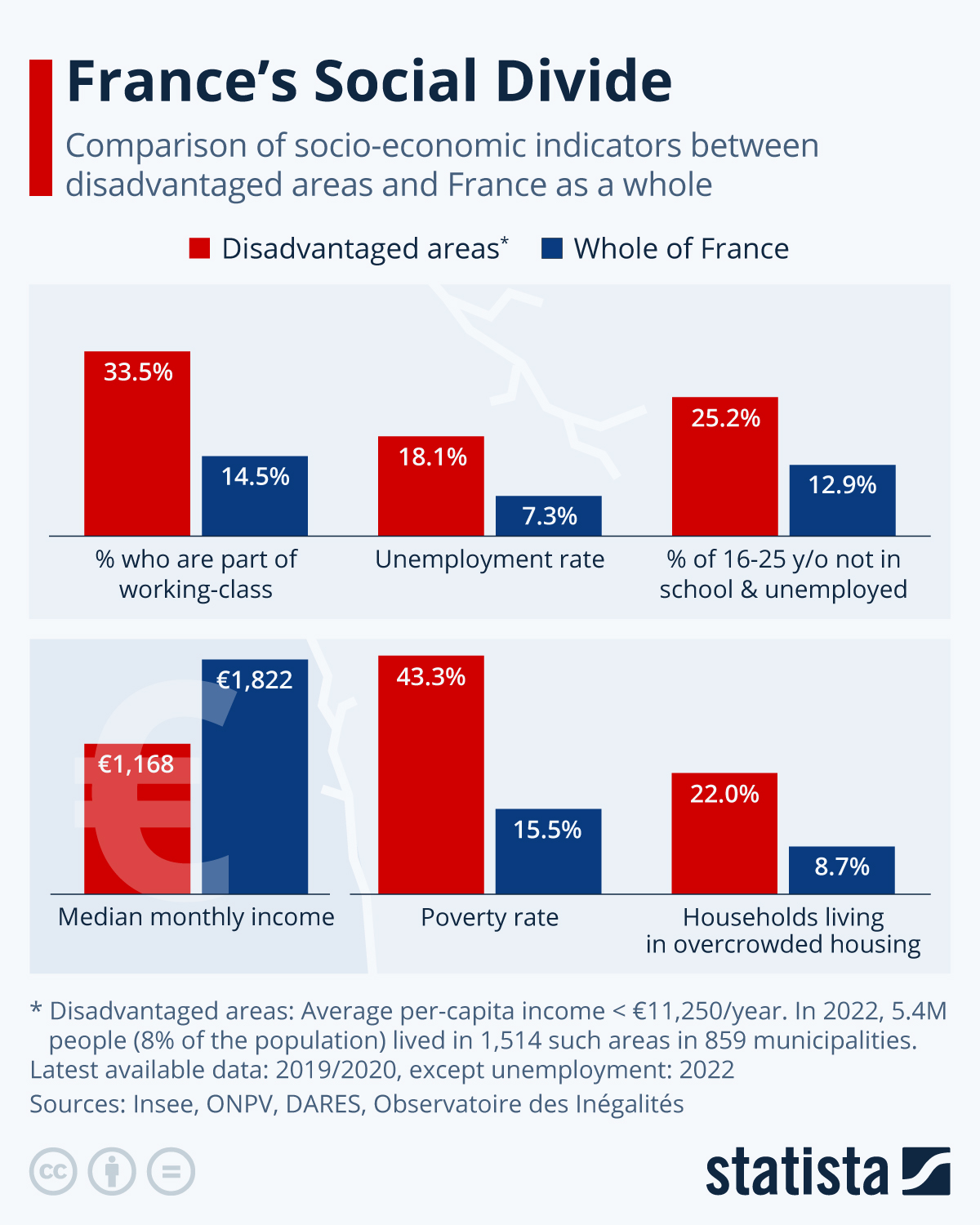
curl https://api.mistral.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-d '{
"model": "ministral-14b-latest",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": "https://cdn.statcdn.com/Infographic/images/normal/30322.jpeg"
}
]
}
],
"max_tokens": 300
}'