Document AI - Processeur OCR
L'API Mistral Document AI intègre un processeur OCR (reconnaissance optique de caractères), propulsé par notre dernier modèle OCR mistral-ocr-latest, qui vous permet d'extraire du texte et du contenu structuré à partir de documents PDF.
Avant de commencer
Fonctionnalités principales
- Extrait le texte du contenu tout en préservant la structure et la hiérarchie du document.
- Préserve la mise en forme comme les en-têtes, paragraphes, listes et tableaux.
- Le formatage des tableaux peut basculer entre
null,markdownethtmlvia le paramètretable_format.null: les tableaux sont retournés en ligne sous forme de markdown dans la page extraite.markdown: les tableaux sont retournés séparément sous forme de tableaux markdown.html: les tableaux sont retournés séparément sous forme de tableaux html.
- Le formatage des tableaux peut basculer entre
- Option pour extraire les en-têtes et pieds de page via les paramètres
extract_headeretextract_footer. Lorsqu'ils sont utilisés, le contenu des en-têtes et pieds de page sera fourni dans les champsheaderetfooter. Par défaut, les en-têtes et pieds de page sont considérés comme faisant partie du contenu principal. - Option permettant d’extraire les boîtes englobantes au niveau des paragraphes et les étiquettes de blocs structurels via le paramètre
include_blocks. Lorsqu’elle est activée, chaque page contient un tableaublockslistant chaque bloc (text, title, list, table, image, equation, caption, code, references, aside_text, header, footer, signature) dans l’ordre de lecture, avec sa boîte englobante et son contenu. - Retourne les résultats au format markdown pour une analyse et un rendu faciles.
- Gère les mises en page complexes incluant le texte en plusieurs colonnes et le contenu mixte, et retourne les hyperliens lorsqu'ils sont disponibles.
- Fournit des scores de confiance pour le contenu extrait au niveau du mot ou de la page via le paramètre
confidence_scores_granularity. - Traite les documents à grande échelle avec une grande précision.
- Prend en charge plusieurs formats de documents, notamment :
image_url: png, jpeg/jpg, avif et plus encore...document_url: pdf, pptx, docx et plus encore...- Pour une liste plus complète (non exhaustive), consultez notre FAQ.
Découvrez-en plus sur notre API ici.
La mise en forme des tableaux ainsi que l’extraction des en-têtes et pieds de page ne sont disponibles que pour OCR 2512 ou versions ultérieures.
L’extraction des blocs via include_blocks n’est disponible que pour OCR 4 (mistral-ocr-4-0) ou versions ultérieures.
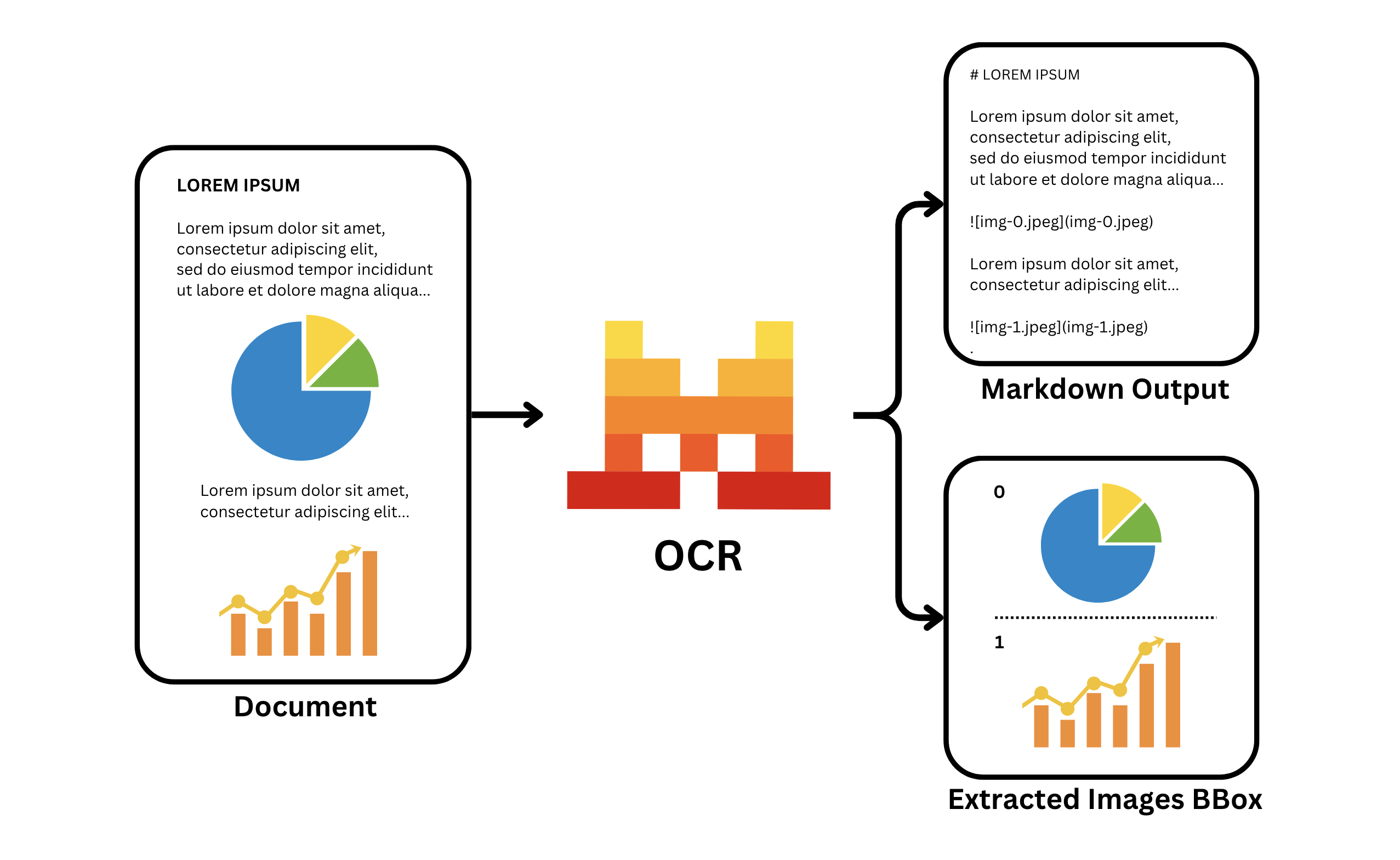
Le processeur OCR retourne le contenu textuel extrait, les bboxes des images et les métadonnées concernant la structure du document, facilitant ainsi le travail programmatique avec le contenu reconnu.
OCR avec images et PDF
OCR de vos documents
Nous proposons différentes méthodes pour effectuer l'OCR de vos documents. Vous pouvez traiter un PDF ou une image.
Parmi les méthodes PDF, vous pouvez utiliser une URL publiquement accessible, un PDF encodé en base64 ou télécharger un PDF dans notre Cloud.
Assurez-vous que l'URL est publique et accessible par notre API.
import os
from mistralai.client import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2201.04234"
},
table_format="html", # default is None
# extract_header=True, # default is False
# extract_footer=True, # default is False
include_image_base64=True
)Le résultat sera un objet JSON contenant le contenu textuel extrait, les bboxes des images, les métadonnées et d'autres informations sur la structure du document.
{
"pages": [ # Le contenu de chaque page
{
"index": int, # L'index de la page correspondante
"markdown": str, # Le résultat principal et le contenu markdown brut
"images": list, # Informations sur les images lorsque celles-ci sont extraites
"tables": list, # Informations sur les tableaux lors de l'utilisation de `table_format=html` ou `table_format=markdown`
"hyperlinks": list, # Hyperliens détectés
"header": str|null, # Contenu de l'en-tête lors de l'utilisation de `extract_header=True`
"footer": str|null, # Contenu du pied de page lors de l'utilisation de `extract_footer=True`
"dimensions": dict, # Les dimensions de la page
"confidence_scores": dict|null, # Scores de confiance lorsque `confidence_scores_granularity` est défini (contient `average_page_confidence_score`, `minimum_page_confidence_score` et `word_confidence_scores` pour la granularité au niveau du mot)
"blocks": list|null # Boîtes englobantes au niveau des paragraphes avec étiquettes de blocs lors de l'utilisation de `include_blocks=True`
}
],
"model": str, # Le modèle utilisé pour l'OCR
"document_annotation": dict|null, # Informations d'annotation du document lorsqu'utilisées, consultez la documentation Annotations pour plus d'informations
"usage_info": dict # Informations d'utilisation
}Lors de l'extraction d'images et de tableaux, ceux-ci seront remplacés par des balises de remplacement, telles que :
[tbl-3.html](tbl-3.html)
Vous pouvez les associer aux images et tableaux réels en utilisant les champs images et tables.
Images
Pour effectuer l'OCR sur une image, vous pouvez soit transmettre une URL vers l'image, soit utiliser directement une image encodée en Base64.
Vous pouvez effectuer de l'OCR avec n'importe quelle image publique tant qu'une URL directe est disponible.
import os
from mistralai.client import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": "https://raw.githubusercontent.com/mistralai/cookbook/refs/heads/main/mistral/ocr/receipt.png"
},
# table_format=None,
include_image_base64=True
)Le résultat sera un objet JSON contenant le contenu textuel extrait, les bboxes des images, les métadonnées et d'autres informations sur la structure du document.
{
"pages": [ # Le contenu de chaque page
{
"index": int, # L'index de la page correspondante
"markdown": str, # Le résultat principal et le contenu markdown brut
"images": list, # Informations sur les images lorsque celles-ci sont extraites
"tables": list, # Informations sur les tableaux lors de l'utilisation de `table_format=html` ou `table_format=markdown`
"hyperlinks": list, # Hyperliens détectés
"header": str|null, # Contenu de l'en-tête lors de l'utilisation de `extract_header=True`
"footer": str|null, # Contenu du pied de page lors de l'utilisation de `extract_footer=True`
"dimensions": dict, # Les dimensions de la page
"confidence_scores": dict|null, # Scores de confiance lorsque `confidence_scores_granularity` est défini (contient `average_page_confidence_score`, `minimum_page_confidence_score` et `word_confidence_scores` pour la granularité au niveau du mot)
"blocks": list|null # Boîtes englobantes au niveau des paragraphes avec étiquettes de blocs lors de l'utilisation de `include_blocks=True`
}
],
"model": str, # Le modèle utilisé pour l'OCR
"document_annotation": dict|null, # Informations d'annotation du document lorsqu'utilisées, consultez la documentation Annotations pour plus d'informations
"usage_info": dict # Informations d'utilisation
}Lors de l'extraction d'images et de tableaux, ceux-ci seront remplacés par des balises de remplacement, telles que :
[tbl-3.html](tbl-3.html)
Vous pouvez les associer aux images et tableaux réels en utilisant les champs images et tables.
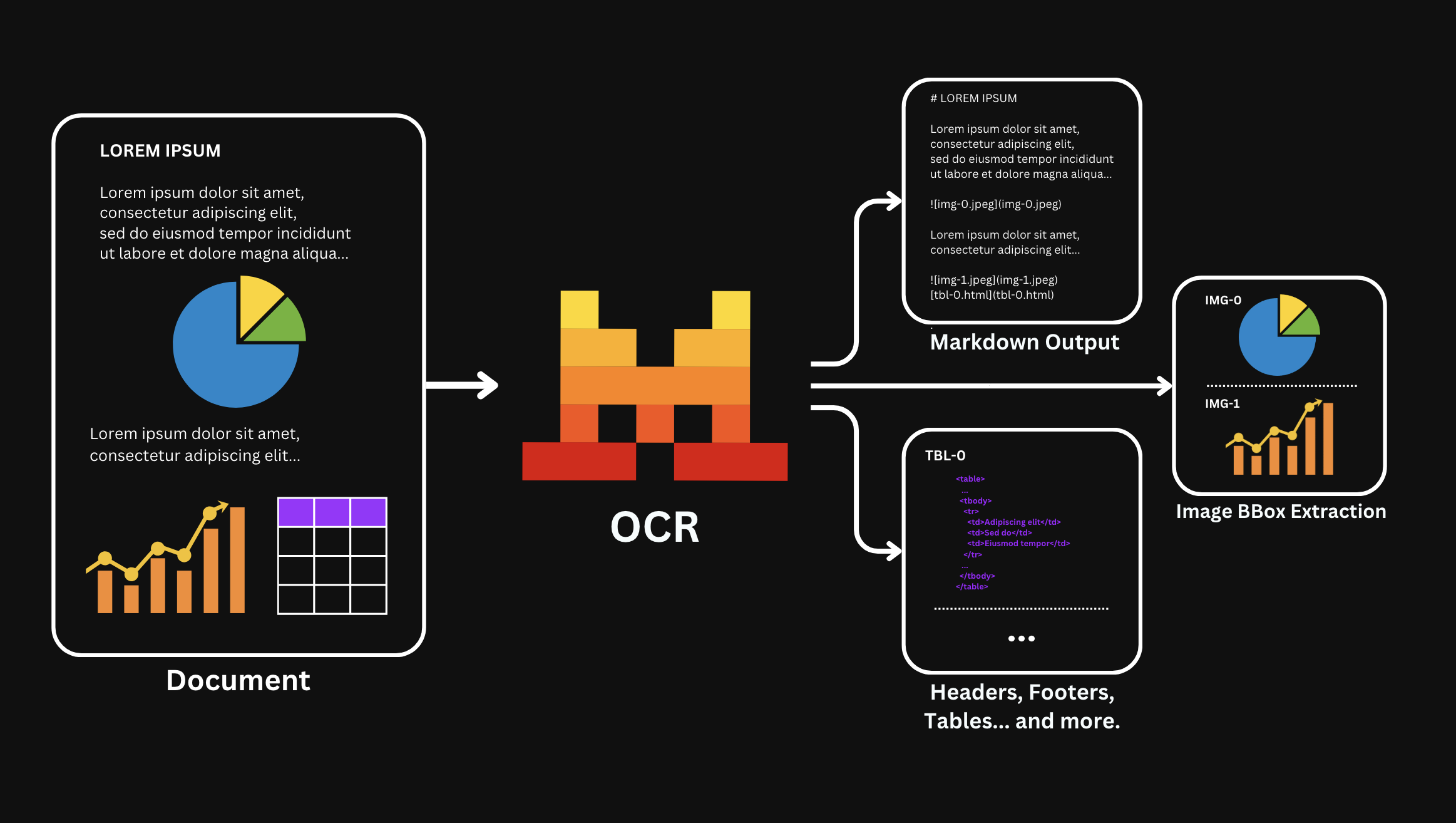
Extraction des blocs
Extraire les blocs structurels avec des boîtes englobantes
Définissez include_blocks=True pour recevoir un tableau blocks sur chaque page. Chaque bloc décrit une zone de contenu spécifique avec son libellé (type), les coordonnées de sa boîte englobante et le contenu extrait. Les blocs sont renvoyés dans l’ordre de lecture.
Chaque bloc partage les champs suivants : type, top_left_x, top_left_y, bottom_right_x, bottom_right_y, et content.
Types de blocs disponibles
| Type de bloc | Description |
|---|---|
text | Un paragraphe de texte principal. |
title | Un titre de document ou de section. |
list | Une liste à puces ou numérotée. |
table | Une zone de tableau. Lorsqu’un tableau est extrait, inclut un table_id référençant l’entrée correspondante dans tables. |
image | Une zone d’image. Inclut un image_id référençant l’entrée correspondante dans images. |
equation | Une équation mathématique. |
caption | Une légende associée à une figure ou un tableau. |
code | Un bloc de code. |
references | Une section de bibliographie ou de références. |
aside_text | Un encadré, une note latérale ou un bloc de texte marginal. |
header | L’en-tête de page. |
footer | Le pied de page. |
signature | Une zone de signature. Le champ content contient le nom transcrit lorsqu’il est lisible, sinon une chaîne vide. |
import os
from mistralai.client import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2201.04234"
},
include_blocks=True
)L’extraction des blocs n’est disponible que pour OCR 4 (mistral-ocr-4-0) ou versions ultérieures. Les anciens modèles acceptent le paramètre mais renvoient un tableau vide.
Scores de confiance
Extraire les scores de confiance
Le processeur OCR peut renvoyer des scores de confiance pour le contenu extrait afin de vous aider à évaluer la qualité de la reconnaissance. Utilisez le paramètre confidence_scores_granularity pour contrôler le niveau de détail :
| Valeur | Description |
|---|---|
"page" | Renvoie un objet confidence_scores sur chaque page avec des statistiques agrégées (average_page_confidence_score, minimum_page_confidence_score). |
"word" | Renvoie tout ce que renvoie "page", plus un tableau word_confidence_scores avec les valeurs de confiance par mot sur chaque page et chaque entrée de tableau. |
import os
from mistralai.client import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2201.04234"
},
confidence_scores_granularity="word" # or "page" for aggregate only
)OCR à grande échelle
Lorsque vous effectuez de l'OCR à grande échelle, nous recommandons d'utiliser notre service d'inférence par lots, qui vous permet de traiter de grandes quantités de documents en parallèle tout en étant plus économique que l'utilisation directe de l'API OCR. Nous prenons également en charge les Annotations pour les sorties structurées et d'autres fonctionnalités.
Cookbooks
Pour plus d'informations et de guides sur l'utilisation de l'OCR, nous avons les cookbooks suivants :