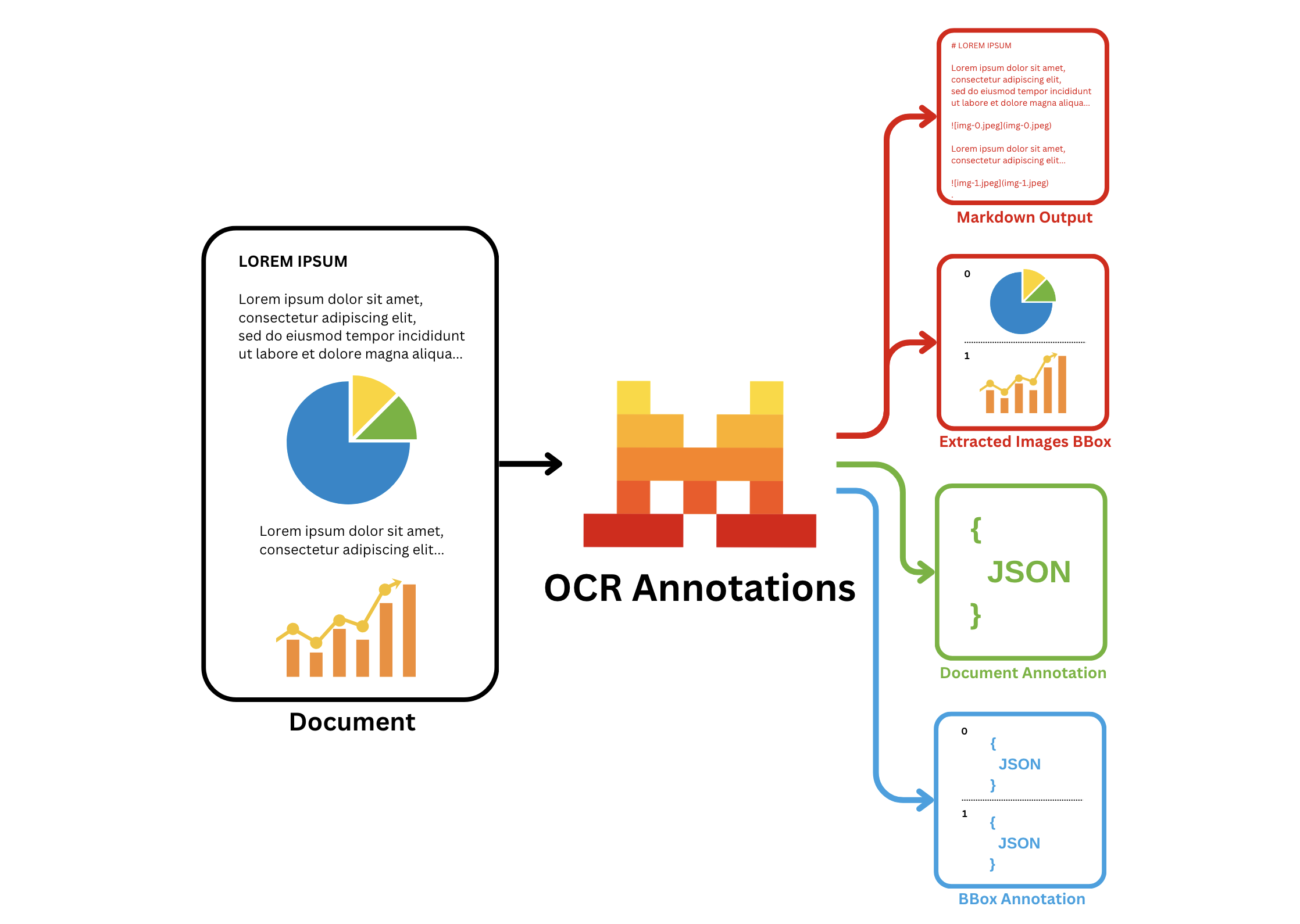
Annotations
En plus de la fonctionnalité OCR de base, l'API Document AI de Mistral ajoute la fonctionnalité annotations, qui permet d'extraire des informations dans un format json structuré que vous fournissez.
Avant de commencer
Que pouvez-vous faire avec les Annotations ?
Plus précisément, elle propose deux types d'annotations :
bbox_annotation: fournit l'annotation des bboxes extraites par le modèle OCR (graphiques, figures, etc.) en fonction des exigences de l'utilisateur et du format d'annotation bbox/image fourni. L'utilisateur peut par exemple demander de décrire ou légender la figure.document_annotation: renvoie l'annotation de l'ensemble du document en fonction du format d'annotation de document fourni.
Fonctionnalités clés
- Étiquetage et annotation de données
- Extraction et structuration d'informations spécifiques de documents dans un format JSON prédéfini
- Automatisation de l'extraction de données pour réduire la saisie manuelle et les erreurs
- Traitement efficace de grands volumes de documents pour les applications d'entreprise
Cas d'usage courants
- Analyse de formulaires, classification de documents et traitement d'images, incluant texte, graphiques et signatures
- Conversion de graphiques en tableaux, extraction de texte en petits caractères à partir de figures, ou définition de types d'images personnalisés
- Capture de données de reçus, incluant les noms de marchands et les montants de transactions, pour la gestion des dépenses.
- Extraction d'informations clés telles que les détails des fournisseurs et les montants à partir de factures pour une comptabilité automatisée.
- Extraction de clauses et termes clés de contrats pour faciliter la révision et la gestion
Fonctionnement
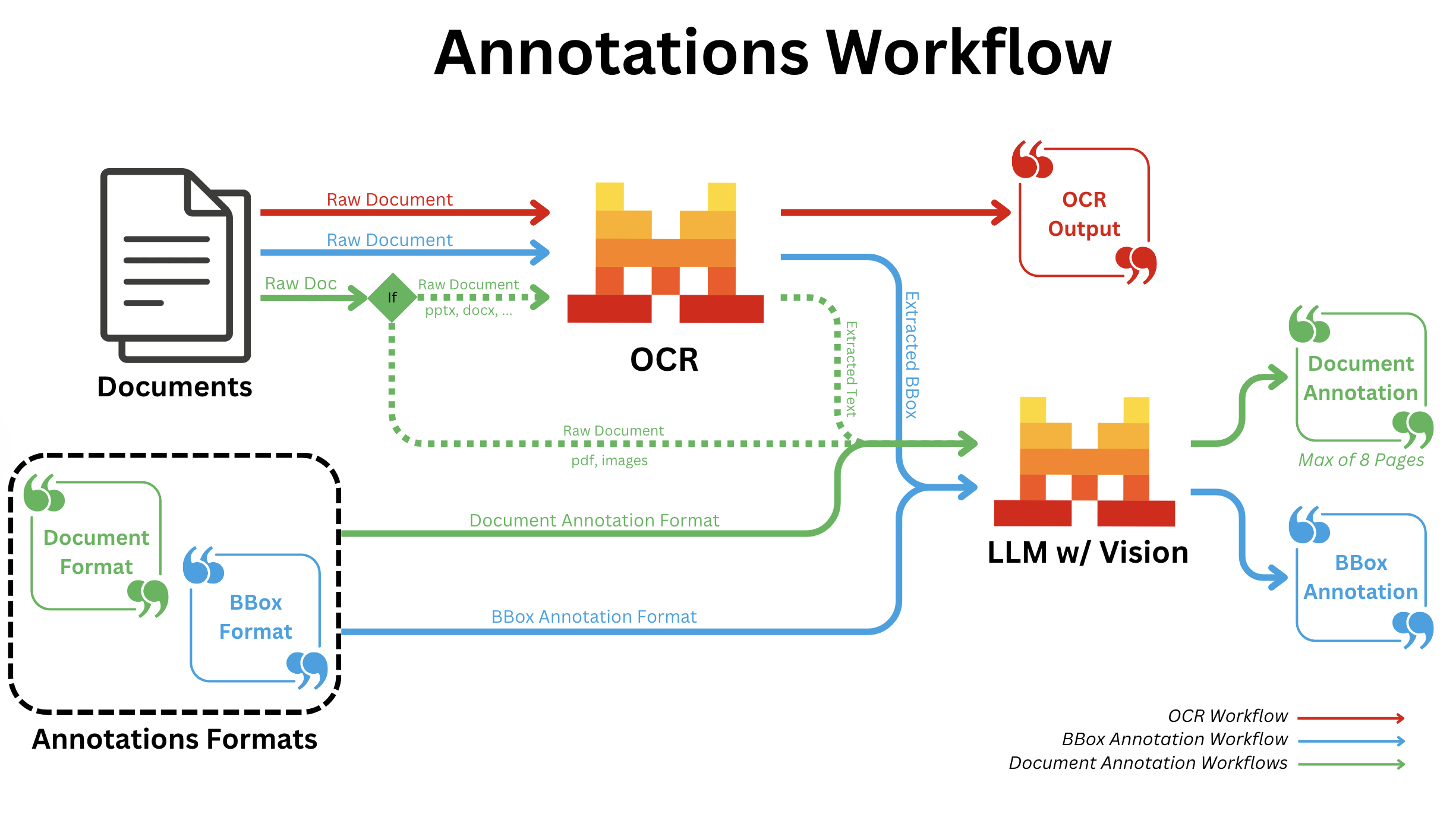
Annotations BBOX
- Tous types de documents :
- Une fois l'OCR standard terminé, nous appelons un LLM capable de vision pour toutes les bboxes individuellement avec le format d'annotation fourni.
Annotation de document
- Tous types de documents :
- Nous exécutons l'OCR et envoyons le texte de sortie en Markdown, accompagné des huit premières bounding boxes d'images extraites, à un LMM capable de vision, avec le format d'annotation fourni.
Formats acceptés
Vous pouvez utiliser notre API avec les formats de documents suivants :
- OCR avec PDF
- OCR avec image : même à partir de sources de faible qualité ou manuscrites.
- scans, DOCX, PPTX...
Dans les extraits de code ci-dessous, nous considérerons le format OCR avec PDF.
Utilisation
Comment annoter
Comme mentionné précédemment, vous pouvez soit :
- Utiliser la fonctionnalité
bbox_annotation, permettant d'extraire des informations à partir des bboxes du document. - Utiliser la fonctionnalité
document_annotation, permettant d'extraire des informations de l'ensemble du document.- En option, nous proposons également la possibilité d'ajouter un
document_annotation_prompt, un prompt général de haut niveau pour guider et instruire sur la manière d'annoter le document.
- En option, nous proposons également la possibilité d'ajouter un
- Utiliser les deux fonctionnalités simultanément.
Voici un exemple d'utilisation de nos fonctionnalités d'annotation BBox.
Définir le modèle de données
Tout d'abord, définissez les formats de réponse pour BBox Annotation, en utilisant soit des schémas Pydantic ou Zod pour nos SDK, soit un schéma JSON pour un appel API curl.
Les schémas Pydantic/Zod/JSON acceptent des objets imbriqués, des tableaux, des énumérations, etc.
from pydantic import BaseModel
# BBOX Annotation response formats
class Image(BaseModel):
image_type: str
short_description: str
summary: strVous pouvez également fournir une description pour chaque entrée ; la description sera utilisée comme information détaillée et instructions pendant l'annotation ; par exemple :
from pydantic import BaseModel, Field
# BBOX Annotation response formats
class Image(BaseModel):
image_type: str = Field(..., description="The type of the image.")
short_description: str = Field(..., description="A description in english describing the image.")
summary: str = Field(..., description="Summarize the image.")Démarrer la requête
Ensuite, effectuez une requête et assurez-vous que la réponse respecte les structures définies en utilisant bbox_annotation_format défini sur les schémas correspondants :
import os
from mistralai.client import Mistral, DocumentURLChunk, ImageURLChunk, ResponseFormat
from mistralai.extra import response_format_from_pydantic_model
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
response = client.ocr.process(
model="mistral-ocr-latest",
document=DocumentURLChunk(
document_url="https://arxiv.org/pdf/2410.07073"
),
bbox_annotation_format=response_format_from_pydantic_model(Image),
include_image_base64=True
)Exemple de sortie d'annotation BBox
La fonctionnalité BBox Annotation permet d'extraire des données et d'annoter des images qui ont été extraites du document original. Ci-dessous, vous avez l'une des images d'un document extraite par notre processeur OCR.
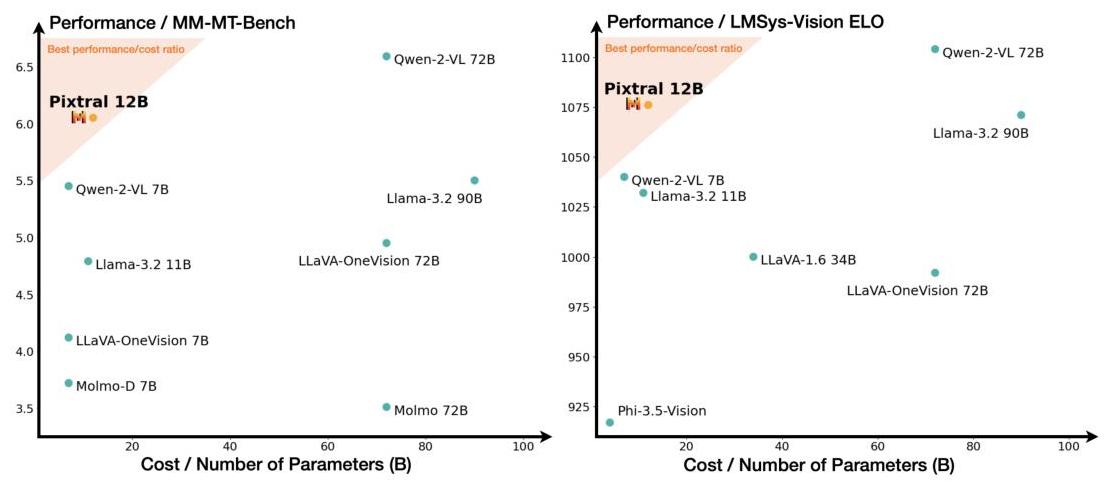
L'image extraite est fournie dans un format encodé en base64.
{
"image_base64": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGB{LONG_MIDDLE_SEQUENCE}KKACiiigAooooAKKKKACiiigD//2Q==..."
}Et vous pouvez annoter l'image avec le schéma de modèle que vous souhaitez. Ci-dessous, vous avez un exemple de sortie.
{
"image_type": "scatter plot",
"short_description": "Comparison of different models based on performance and cost.",
"summary": "The image consists of two scatter plots comparing various models on two different performance metrics against their cost or number of parameters. The left plot shows performance on the MM-MT-Bench, while the right plot shows performance on the LMSys-Vision ELO. Each point represents a different model, with the x-axis indicating the cost or number of parameters in billions (B) and the y-axis indicating the performance score. The shaded region in both plots highlights the best performance/cost ratio, with Pixtral 12B positioned within this region in both plots, suggesting it offers a strong balance of performance and cost efficiency. Other models like Qwen-2-VL 72B and Qwen-2-VL 7B also show high performance but at varying costs."
}Cookbooks
Pour plus d'informations et de guides sur l'utilisation de l'OCR, nous disposons des cookbooks suivants :