API de fine-tuning (ancienne version)
Obsolète
Cette fonctionnalité est obsolète et n'est plus activement maintenue.
Lors de la création d'une application avec un LLM, vous pouvez vouloir personnaliser le modèle pour mieux l'adapter à votre cas d'usage. Ce guide vous accompagne dans le processus de personnalisation d'un modèle pour votre application.
Vue d'ensemble
Comment créer une application avec un modèle personnalisé
Voici un guide rapide pour créer une application avec un modèle personnalisé. Notre objectif est d'aider les développeurs à mettre en place des opérations produit pour les LLM afin de passer du prototype au déploiement.
L'IA est un outil : créer des applications qui exploitent l'IA les rend plus utiles et pratiques pour vos utilisateurs finaux.
Avant les LLM, les applications IA étaient construites autour de la personnalisation, de la précision et de la prédiction. Les applications IA traditionnelles visent à prédire votre prochain choix et à vous le recommander en fonction de votre comportement passé et de celui « d'utilisateurs similaires ».
En revanche, les applications LLM sont construites autour de la collaboration humain-IA. En tant que développeur et utilisateur final, vous avez plus de contrôle sur la personnalisation de votre produit. Vous pouvez créer quelque chose qui n'existait pas auparavant.
Les applications construites avec des LLM personnalisés nécessitent un cycle de développement itératif, s'appuyant sur des retours utilisateurs continus et des évaluations rigoureuses pour garantir que le comportement de votre modèle personnalisé est aligné sur le comportement attendu de l'application.
Nous proposons quelques exemples de personnalisation de modèle via le Fine-Tuning ici.
Termes clés
Avant de commencer, définissons les termes clés :
Le comportement de l'application peut être défini comme l'interaction utilisateur. Il prend en compte l'utilisabilité, les performances, la sécurité et l'adaptabilité. Le comportement de l'application inclut les objectifs et les valeurs.
Le comportement du modèle peut être défini comme la manière attendue, appropriée et acceptable dont un LLM agit dans un contexte spécifique ou dans les limites d'une application. Le comportement du modèle inclut les objectifs et les valeurs.
Les objectifs déterminent si le comportement du modèle est conforme au comportement attendu de l'application.
Les valeurs désignent la politique prévue par les développeurs pour le modèle et l'application. Il peut s'agir d'un ensemble de règles, d'une Constitution ou même des principes moraux d'un personnage fictif.
Pilotage : trois méthodes
Plusieurs techniques (avec différents niveaux de complexité technique) sont disponibles pour piloter le comportement du modèle dans le contexte de votre application. Nous recommandons d'utiliser les trois méthodes suivantes :
- Prompt système
- Entraîner un modèle
- Déployer une couche de modération pour le traitement des entrées/sorties
Un prompt système est une méthode pour fournir du contexte, des instructions et des directives à votre modèle avant que celui-ci ne traite les données d'entrée de l'utilisateur (guide de prompting). En utilisant un prompt système, vous pouvez orienter le modèle pour mieux l'aligner sur le comportement produit souhaité — que l'application soit conversationnelle ou axée sur une tâche, vous pouvez spécifier un persona, une personnalité, un ton, des valeurs ou toute autre information pertinente susceptible d'aider votre modèle à mieux répondre aux entrées de l'utilisateur final.
Les prompts système peuvent inclure :
- Des instructions et objectifs clairs et précis
- Des rôles, le persona et le ton souhaités
- Des indications sur le style, par exemple des contraintes de verbosité
- Des définitions de valeurs, par exemple des politiques, règles et garde-fous
- Le format de sortie souhaité
Entraîner un modèle est une méthode pour former le modèle sur le comportement attendu de votre application (guide de fine-tuning). Deux approches populaires pour entraîner les LLM :
- Entraînement applicatif, où vous exploitez un jeu de données d'exemples spécifiques au comportement souhaité de votre application.
- Entraînement de sécurité, où vous exploitez un jeu de données qui spécifie à la fois des exemples d'entrées susceptibles de produire un comportement non sécurisé, ainsi que la sortie sécurisée souhaitée dans cette situation.
Déployer un classificateur pour la modération de contenu est une troisième méthode pour créer des garde-fous pour le comportement de votre modèle au sein de l'application. Cela est considéré comme une mesure de sécurité supplémentaire si vous déployez votre application auprès d'utilisateurs finaux.
Guide pour entraîner un modèle selon le comportement applicatif souhaité
Voici un guide étape par étape pour vous aider à créer votre application avec un modèle personnalisé.
Étape 1 : Définir le comportement applicatif souhaité
La première étape consiste à définir les objectifs, c'est-à-dire comment vous souhaitez que les utilisateurs interagissent avec votre produit LLM.
Pour vous inspirer, observez les développeurs qui construisent avec les modèles Mistral :
- des produits autonomes comme des assistants conversationnels ;
- au sein de produits préexistants pour accomplir une tâche spécifique comme « Résumer » ou « Traduire » ou activer de nouvelles capacités comme l'appel de fonctions avec accès API pour la « Récupération de connaissances ».
Découvrez comment d'autres créent des produits avec des modèles personnalisés ici : exemples de développeurs.
Étape 2 : Définir vos politiques en fonction de vos valeurs
Lorsque vous déployez un LLM dans une application destinée aux utilisateurs finaux, vous identifiez quelles valeurs le modèle devra respecter afin de répondre à vos directives de modération de contenu ainsi qu'aux attentes de vos utilisateurs.
Pour la modération de contenu, inspirez-vous des catégories de Llama Guard comme la confidentialité, la haine et les conseils spécialisés, ainsi que des catégories de ML Commons Taxonomy comme CSAM et la haine.
Étape 3 : Créer vos évaluations d'application
L'objectif de vos évaluations est de vous permettre d'avoir un meilleur signal sur la question de savoir si le comportement de votre modèle personnalisé répondra à votre comportement applicatif avant le déploiement. Identifier comment vous souhaitez évaluer votre modèle personnalisé aidera à déterminer le type de données d'entraînement à inclure dans le fine-tuning.
Il existe deux méthodes pour évaluer un LLM :
- Évaluations automatisées
- Basées sur des métriques, similaires aux évaluations de référence publiques où vous pouvez dériver une métrique à partir de données pré-annotées par exemple.
- Basées sur un LLM, où vous exploitez un LLM différent comme Mistral Large pour évaluer ou juger la sortie de votre modèle personnalisé.
- Évaluations humaines, où vous employez des annotateurs de contenu pour évaluer ou juger la sortie de votre modèle personnalisé et collecter des annotations humaines.
Pour en savoir plus sur la conduite d'une évaluation de LLM, consultez notre guide d'évaluation.
Étape 4 : Tester votre hypothèse de comportement applicatif avec un MVP
Une fois que vous comprenez l'intention de votre LLM personnalisé et les contours de la façon dont vous souhaitez que le modèle se comporte, commencez par tester votre hypothèse d'application avec Mistral Large et collectez les données d'interaction pour mieux comprendre comment vos utilisateurs finaux peuvent interagir avec votre LLM. Par exemple, de nombreux développeurs commencent leur processus en créant une démo ou un MVP avec un accès limité en Public Preview.
Pour certaines applications, un prompt système est la meilleure solution pour obtenir un comportement de modèle aligné. Si vous avez besoin d'aide pour choisir entre les deux, consultez notre guide de fine-tuning.
Si un prompt système fonctionne pour créer un modèle personnalisé, passez à l'étape 6.
Étape 5 : Entraîner pour l'alignement du modèle
Maintenant que vous avez une idée du comportement applicatif — valeurs et objectifs inclus — que vous avez l'intention d'adopter avec un modèle personnalisé, vous pouvez commencer le processus de remplacement de Mistral Large par un modèle plus petit et personnalisé.
Consultez notre guide sur la façon de préparer votre jeu de données d'entraînement.
Points à considérer lors de la préparation de votre jeu de données d'entraînement pour de meilleures performances du modèle :
- Compréhension des données, incluez toutes les politiques de contenu pour chaque cas d'usage d'application dans votre jeu de données (comme les questions-réponses, la synthèse et le raisonnement).
- Variété des données, assurez la diversité du jeu de données en termes de longueur de requête, structure, ton, sujet, niveaux de complexité et considérations démographiques.
- Déduplication, supprimez les doublons pour éviter que vos données d'entraînement ne soient mémorisées.
- Éviter la contamination des données, isolez les données d'évaluation du jeu de données d'entraînement.
- Pratiques éthiques des données, fournissez des directives d'étiquetage claires et une diversité d'annotateurs pour minimiser les erreurs et les biais du modèle.
Pour la modération de contenu, commencez avec des jeux de données open source comme Safety-Tuned LlaMAs.
Chez Mistral, nous supportons deux façons de personnaliser nos modèles :
- OSS avec le FT Codebase
- Via AI Studio
Rendez-vous sur notre API FT dans AI Studio, chargez et validez vos données d'entraînement. Lancez le job et, une fois terminé, vous pouvez accéder à votre modèle personnalisé via votre propre endpoint d'API de modèle.
Étape 6 : Tester votre modèle personnalisé avec vos évaluations
Maintenant que vous avez votre endpoint d'API de modèle personnalisé, vous pouvez exécuter les évaluations d'application de l'étape 4. Selon votre application, n'oubliez pas d'inclure des évaluations de sécurité dans votre ensemble d'évaluations :
- Évaluations de développement, incluent des évaluations continues pendant l'entraînement et le fine-tuning pour comparer les performances du modèle par rapport aux critères de lancement et évaluer l'impact des stratégies d'atténuation. Ces évaluations utilisent des requêtes adversariales ou des benchmarks académiques externes.
- Évaluations d'assurance, mettez en place des évaluations de gouvernance et de révision aux étapes clés par un groupe externe. Ces évaluations standardisées utilisent des jeux de données strictement gérés et fournissent des informations de haut niveau pour les efforts d'atténuation. Elles testent les politiques de sécurité et les capacités dangereuses, telles que les risques biologiques, la persuasion et la cybersécurité.
- Red Teaming nécessite des tests adversariaux par des équipes spécialisées utilisant des méthodes moins structurées pour découvrir les faiblesses potentielles et améliorer les approches d'atténuation des risques et d'évaluation.
- Évaluations externes, incluent des évaluations par des experts indépendants externes du domaine pour identifier les limites du modèle et tester en conditions extrêmes les performances.
En fonction des performances du modèle, soit réentraînez votre modèle avec de nouvelles données d'entraînement pour soutenir de meilleures performances, soit déployez-le dans votre application en remplaçant l'API Mistral Large par votre endpoint de modèle personnalisé.
Étape 7 : Une fois déployé, surveiller et mettre à jour en continu
Surveillez et mettez à jour en continu votre modèle personnalisé, vos évaluations et vos tests en fonction des données d'application réelles.
Félicitations ! Vous avez déployé votre modèle personnalisé dans votre application.
Exemples de développeurs
Voici des exemples de développeurs issus de la communauté des startups utilisant notre API de fine-tuning. Consultez notre documentation sur le fine-tuning pour découvrir les avantages du fine-tuning et comment utiliser notre API de fine-tuning.
La vidéo présente le comportement de Tak. Lorsqu'un utilisateur saisit une requête, Tak utilise les connaissances du LLM, un outil de recherche web et un outil de récupération d'actualités pour générer la réponse la plus pertinente à la requête de l'utilisateur. Son comportement dépend du type de requête formulée par l'utilisateur.
Description
Tak est une application de recherche internet B2C propulsée par Mistral Large et d'autres modèles avec RAG et Function Calling.
Afin de fournir la réponse la plus pertinente à la requête de l'utilisateur, plusieurs appels de fonction sont effectués pour catégoriser la demande (voir le diagramme ci-dessous). Les multiples agents étant chaînés, il est crucial de garantir des sorties formatées de manière cohérente.
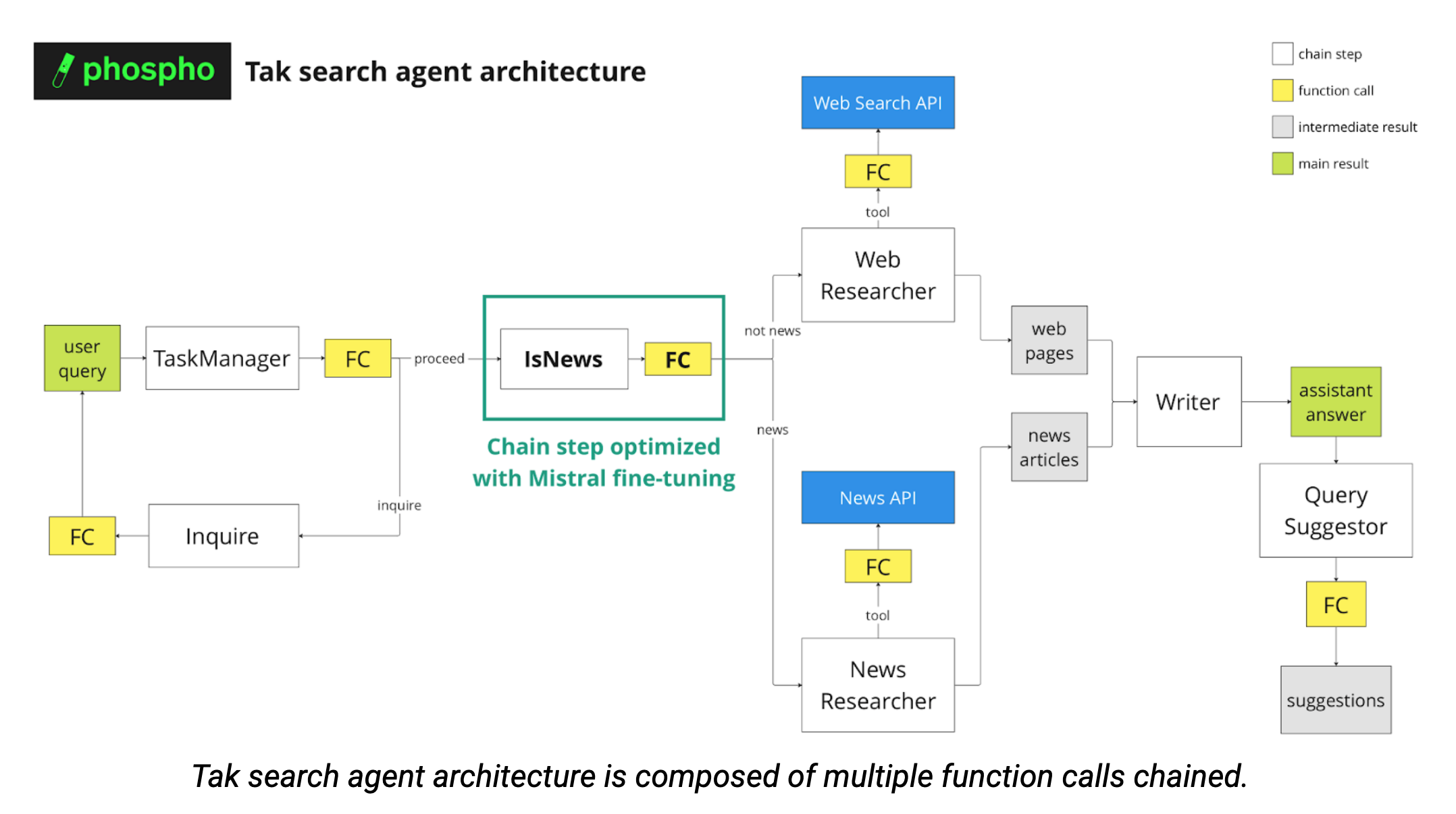
Description de l'entreprise
Chez phospho, nous avons développé le chatbot Tak comme un terrain d'expérimentation pour tester de nouvelles fonctionnalités phospho et démontrer la puissance de l'analytique phospho. L'avantage est que vous pouvez utiliser les données enregistrées dans phospho pour affiner les modèles LLM. Nous sommes phospho, une plateforme d'analytique textuelle open source pour les applications LLM. Des entreprises de toutes tailles utilisent phospho pour comprendre ce que les utilisateurs font avec leur application LLM et comment l'application performe au niveau produit.
Données
Nous avons utilisé un jeu de données de requêtes utilisateur dans Tak et les appels de fonction GPT-4-turbo correspondants, collectés et filtrés via la plateforme phospho. Nous avons ensuite divisé le jeu de données en un ensemble d'entraînement (70 %), un ensemble d'évaluation (15 %) et un ensemble de test (15 %).
Pour déterminer la durée d'entraînement optimale, nous avons suivi la règle empirique selon laquelle chaque token doit être vu trois fois (dans notre cas, 150 étapes d'entraînement, soit environ 10 minutes).
Pour le taux d'apprentissage, nous avons utilisé le taux d'apprentissage suggéré de 6e-5.
Évaluation
Pour évaluer notre modèle affiné, nous exécutons l'inférence sur l'ensemble de test de notre jeu de données, puis utilisons des métriques de classification binaire (Exactitude, Rappel, Score F1). Nous testons si nous avons pu aligner le comportement de Mistral 7b sur le comportement de classification d'OpenAI GPT-4-turbo, tout en maintenant la sortie structurée attendue. En effet, nous avons supprimé le function calling.
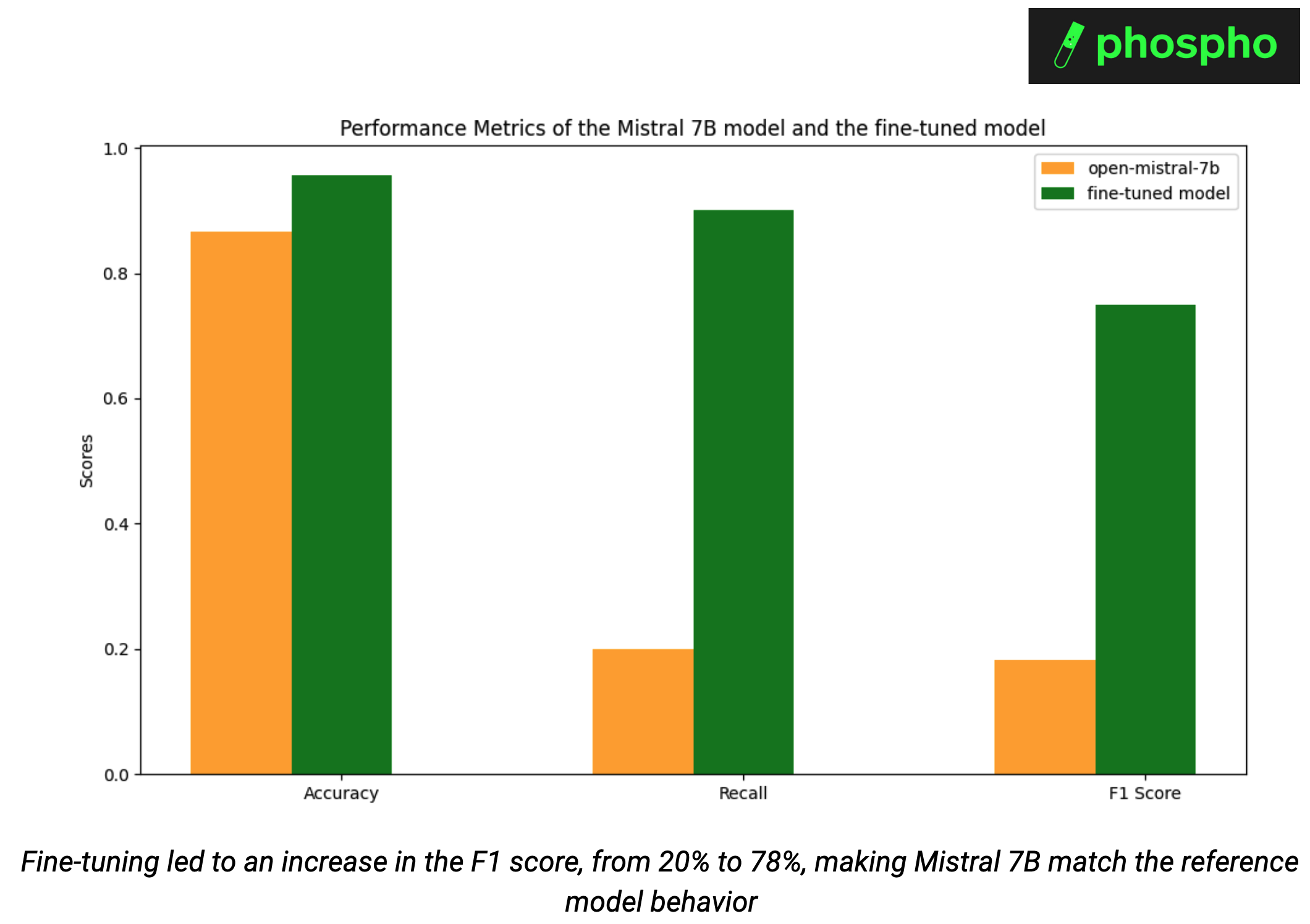
L'affinage a permis à Mistral 7B d'égaler le modèle de référence, augmentant le score F1 de 20 % à 78 %. Sans affinage, Mistral 7B atteignait 87 % d'exactitude et 20 % de rappel sur notre tâche de classification. Avec le modèle affiné, nous avons atteint 96 % d'exactitude et 90 % de rappel.
Comme nous avons affiné le modèle pour qu'il ne réponde qu'avec news_related ou not_news_related, nous n'avons plus besoin d'utiliser le function calling. Cela a conduit à une diminution de 34 % du nombre de tokens utilisés en excluant la requête utilisateur, ce qui réduit encore les coûts.
Conclusion
En conclusion, en combinant la collecte et l'étiquetage de données phospho avec les services d'affinage de Mistral, nous avons considérablement amélioré notre capacité à fournir des réponses précises et pertinentes aux requêtes utilisateur tout en réduisant les coûts. Nous avons aligné avec succès le comportement de Mistral 7B sur celui de GPT-4-turbo. Ce processus d'affinage garantit non seulement un formatage de sortie cohérent, mais réduit également les coûts opérationnels en minimisant l'utilisation de tokens.
Si vous souhaitez également améliorer votre agent RAG, nous vous encourageons à essayer l'affinage avec Mistral en utilisant les données collectées et étiquetées avec phospho. Cela peut conduire à une amélioration significative de votre expérience utilisateur.