Pourquoi l'observabilité ?
L'observabilité est essentielle pour les systèmes de grands modèles de langage (LLM) en phase de prototypage, de test et de production pour plusieurs raisons :
- Visibilité : l'observabilité fournit des informations détaillées sur les états internes des applications LLM, permettant aux développeurs de comprendre le comportement du système. Cette visibilité est cruciale pour identifier et diagnostiquer les problèmes, et pour le débogage.
- Exigence de production : la mise en œuvre de l'observabilité dans les environnements de production répond à des exigences critiques, notamment la surveillance, la scalabilité, la sécurité et la conformité.
- Reproductibilité : l'observabilité permet aux développeurs d'observer et de reproduire le comportement du système LLM.
- Amélioration continue : les informations obtenues à partir des données d'observabilité peuvent être utilisées pour piloter des initiatives d'amélioration continue.
Quels composants observons-nous ?
La réponse courte est : tout et n'importe quoi !
Une application LLM (Large Language Model) peut inclure un ou plusieurs appels LLM. Il est crucial de comprendre à la fois les détails au niveau de chaque appel API individuel et la séquence de ces appels au niveau de l'application :
-
Niveau de l'appel LLM individuel : au niveau de l'appel API LLM individuel, un LLM reçoit un prompt d'entrée et génère une sortie. Nous pouvons donc surveiller et observer trois composants clés : le prompt d'entrée, le modèle et la sortie.
-
Niveau de l'application : au niveau de l'application, il est important d'observer le schéma, la logistique et la séquence des appels LLM. Cette séquence détermine le flux d'informations, l'ordre dans lequel les LLM sont appelés et les tâches qui sont exécutées.
Niveau individuel : quels composants pouvons-nous observer ?
Pour une observabilité efficace, nous devons surveiller et enregistrer des informations détaillées pour chaque version de chaque composant impliqué dans l'interaction avec le LLM. Voici une description de ce qu'il faut observer et quelques modules attendus dans un outil d'observabilité :
Prompt d'entrée
- Template de prompt
- Le format ou la structure standardisé utilisé pour générer le prompt d'entrée, y compris les espaces réservés ou les variables dans le template.
- Les outils d'observabilité fournissent souvent un registre de templates de prompts que la communauté ou une organisation peut utiliser et partager.
- Exemples
- L'apprentissage en contexte avec peu d'exemples (few-shot) est souvent efficace en ingénierie de prompts. Des exemples spécifiques ou des entrées d'échantillons peuvent être utilisés pour guider la réponse du modèle.
- Contexte récupéré
- Dans un système de génération augmentée par récupération (RAG), un contexte pertinent est récupéré à partir de sources externes ou de bases de données pour fournir des informations au LLM, rendant les résultats plus fiables.
- Mémoire
- Données historiques ou interactions précédentes stockées en mémoire.
- Façon dont cette mémoire est utilisée pour influencer le prompt actuel, comme résumer la mémoire passée, récupérer la mémoire pertinente ou utiliser la mémoire la plus récente.
- Outils
- Tout outil ou utilitaire utilisé pour prétraiter ou enrichir le prompt d'entrée.
- Les outils deviennent de plus en plus importants dans les applications LLM, servant de pont vers les applications réelles.
- Configurations spécifiques ou paramètres appliqués par ces outils et leur impact.
Modèle
- Spécifications du modèle
- La version spécifique ou l'identifiant du modèle utilisé.
- Paramètres de configuration, hyperparamètres et toute personnalisation appliquée au modèle.
Sortie
- Formatage
- La structure et le format de la sortie générée par le modèle.
Niveau de l'application : quels schémas de workflow pouvons-nous observer ?
Un système LLM est souvent composé de plus d'un seul LLM. Au niveau de l'application, il existe des schémas de workflow spécifiques qui nécessitent une observabilité spécifique à chaque étape du workflow. Voici quelques exemples de workflows :
- RAG
- Un système RAG inclut l'étape de récupération de documents en plus de l'étape de génération par un LLM. Une observabilité supplémentaire est nécessaire pour suivre et surveiller le document/dataset externe et l'étape de récupération.
- LLM comme partie d'un système
- Un système LLM peut impliquer plusieurs LLM chaînés ensemble, du flow engineering avec diverses itérations, ou un système multi-agents complexe, par exemple pour créer un monde simulé. L'entrée et la sortie de chaque étape doivent être observées pour comprendre le comportement global du système, identifier les goulots d'étranglement et garantir la fiabilité et les performances du système.
Quelles métriques observons-nous ?
À chaque étape du workflow du système LLM, nous pouvons observer les éléments suivants et définir des objectifs de niveau de service (SLO), des alertes et une surveillance globale :
Tokens et coût
- Suivre le nombre de tokens traités et les coûts associés.
Traces et latence
- Tracer le workflow du système pour observer et surveiller la séquence des opérations.
- Mesurer et surveiller la latence pour identifier les goulots d'étranglement de performance et garantir des réponses rapides.
Anomalies et erreurs
- Identifier rapidement les problèmes au sein du système.
- Créer des datasets pour les tests
- Comprendre les schémas et les cas d'usage à partir des cas de retours négatifs par exemple
- Surveiller les taux d'erreur et les retours négatifs dans le temps.
Qualité
Un outil d'observabilité doit permettre de suivre les indicateurs clés de performance par l'évaluation, le retour d'expérience et l'annotation :
- Évaluation
- Métriques et critères utilisés pour mesurer la qualité et la pertinence des résultats.
- Les outils d'observabilité offrent souvent des kits complets pour créer des jeux de données d’évaluation, annoter, évaluer et comparer les résultats des modèles.
- Retour d’expérience
- Avis des utilisateurs sur les résultats, incluant notes, commentaires et suggestions.
- Tout système ou mécanisme automatisé mis en place pour collecter et analyser les retours utilisateurs.
- Annotation
- Annotations manuelles ou automatiques ajoutées aux résultats pour affiner l'analyse et éventuellement enrichir le jeu de données d’évaluation.
Intégrations
Mistral s'intègre avec plusieurs outils d'observabilité pour vous aider à surveiller et garantir des applications LLM plus fiables et performantes.
Intégration avec LangSmith
LangSmith fournit l'observabilité tout au long du cycle de vie du développement d'applications LLM.
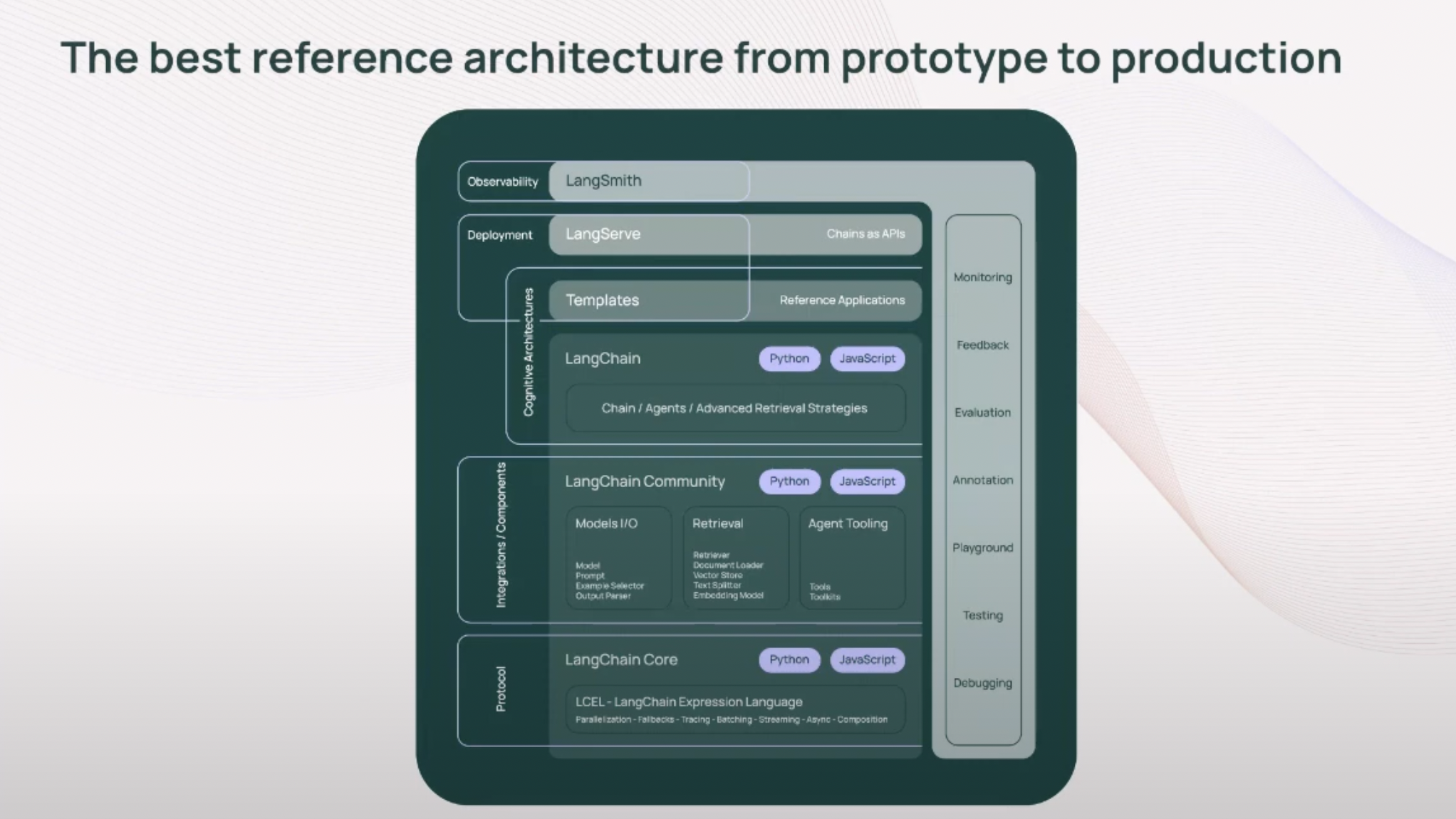
Avantages :
- LangSmith est compatible à la fois avec l'écosystème LangChain et les systèmes externes.
- Option de déploiement bientôt disponible.
- Il offre un large éventail de zones observables, servant de plateforme tout-en-un.
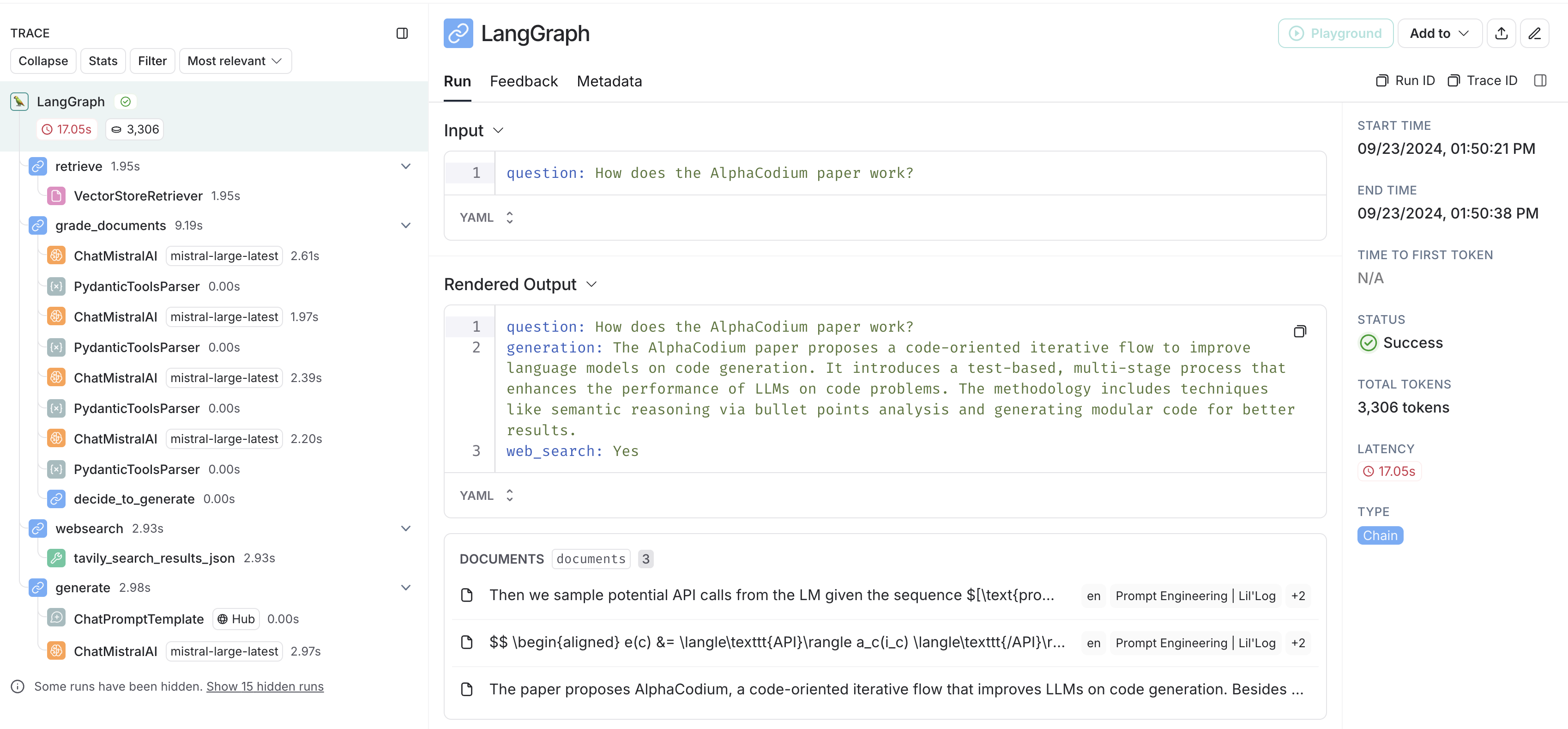
Exemple d'intégration Mistral :
- Tous les notebooks langchain dans le cookbook Mistral incluent l'intégration LangSmith.
Voici un exemple de suivi des traces, entrées, sorties, documents, tokens et statuts lorsque nous exécutons l'exemple de RAG correctif du cookbook Mistral.
Intégration avec Langfuse
Langfuse (GitHub) est une plateforme open source pour l'ingénierie LLM. Elle fournit des capacités de traçage et de surveillance pour les applications d'IA, aidant les développeurs à déboguer, analyser et optimiser leurs produits. Langfuse s'intègre avec divers outils et frameworks via des intégrations natives, OpenTelemetry et des SDK.
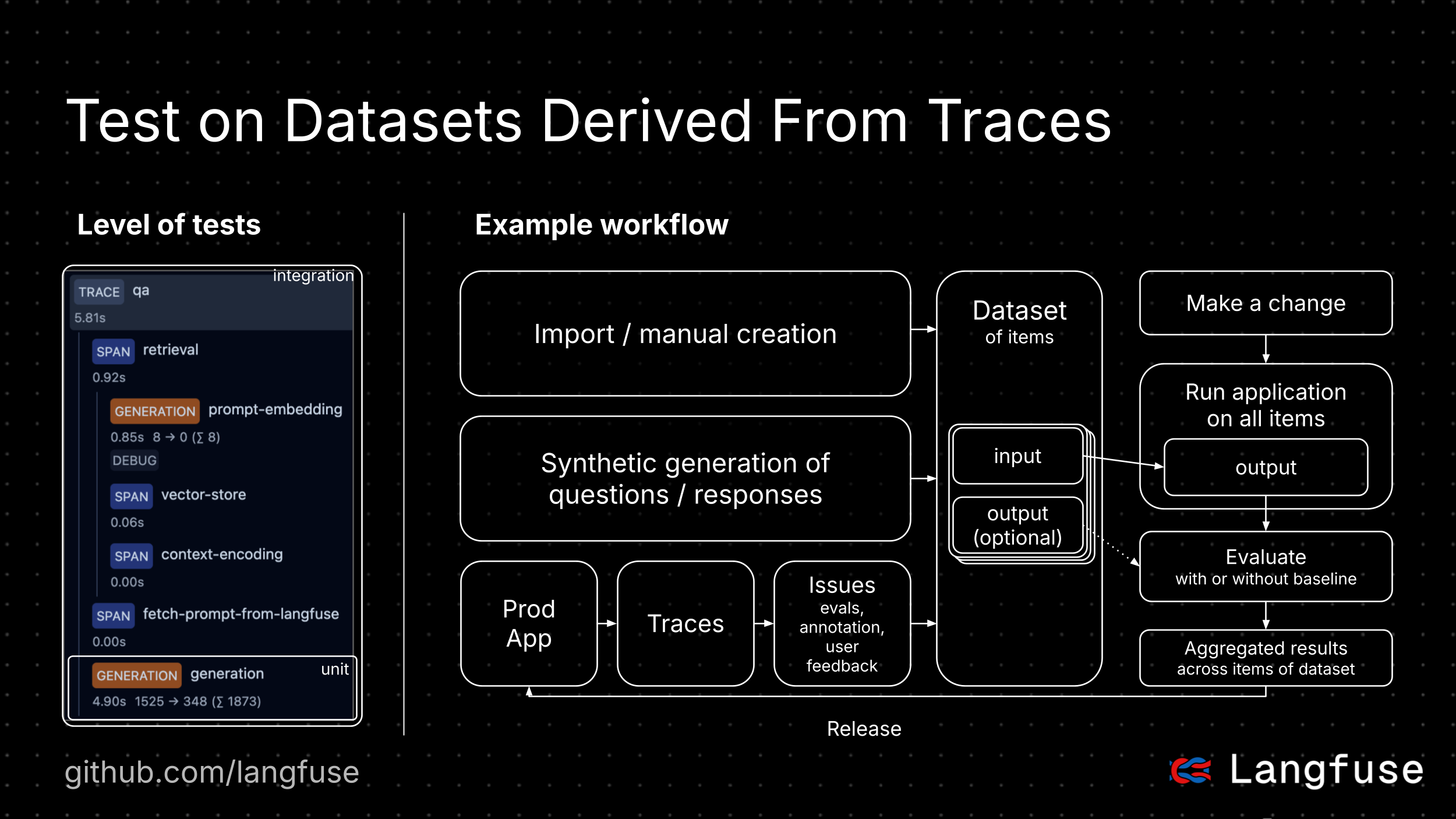
Avantages :
- Plateforme LLMOps open source la plus utilisée (article de blog)
- Agnostique au modèle et au framework
- Conçue pour la production
- Adoptable de manière incrémentale, commencez avec une fonctionnalité et étendez à la plateforme complète au fil du temps
- API-first, toutes les fonctionnalités sont disponibles via API pour des intégrations personnalisées
- En option, Langfuse peut être facilement auto-hébergée
Exemple d'intégration Mistral :
- Guide étape par étape sur le traçage des modèles Mistral avec Langfuse.
- Cookbook sur la construction d'une application RAG avec Mistral et LlamaIndex et le traçage des étapes avec Langfuse.
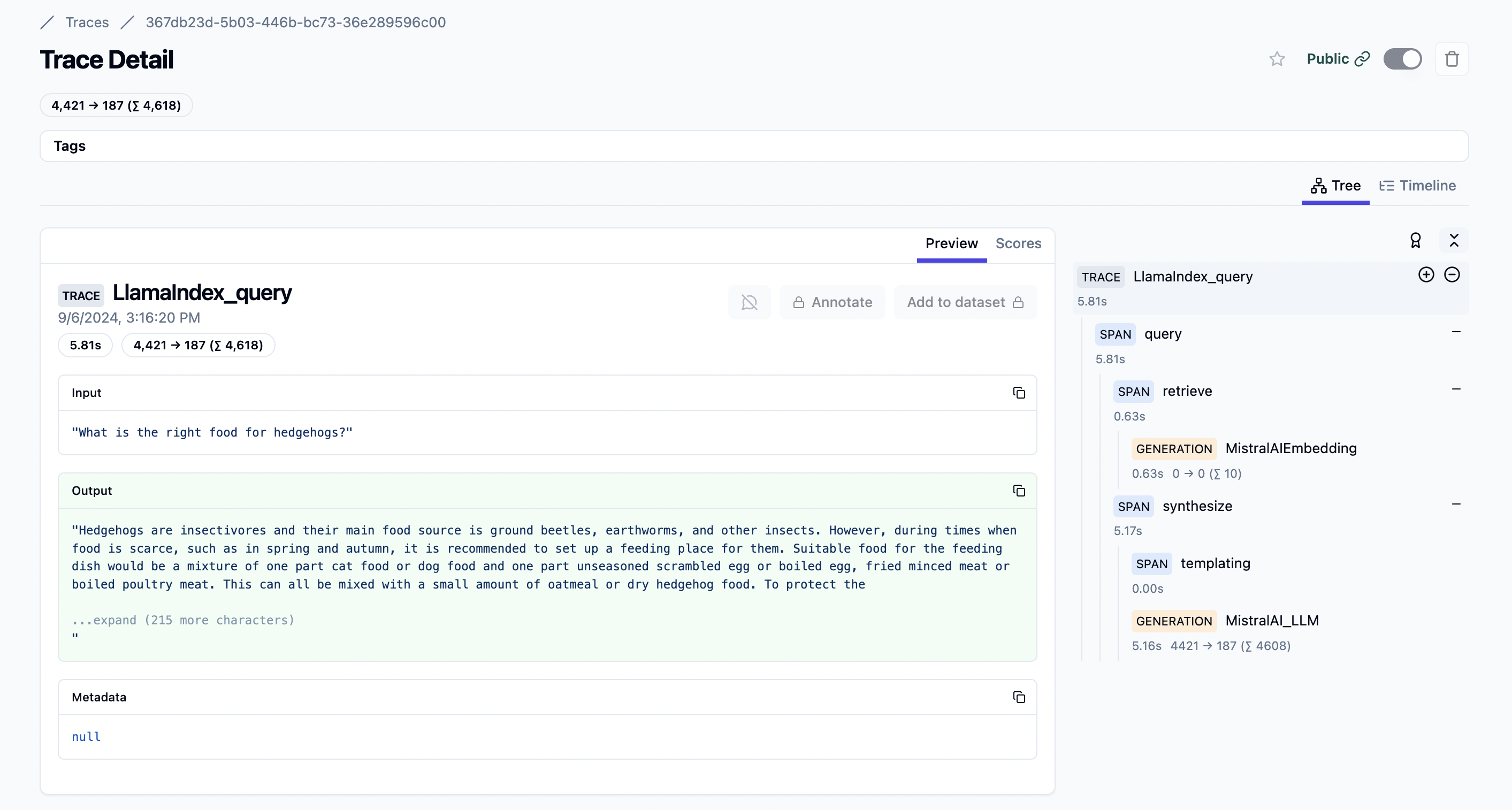
Exemple de trace publique dans Langfuse
Intégration avec Arize Phoenix
Phoenix est une bibliothèque d'observabilité open source conçue pour l'expérimentation, l'évaluation et le dépannage. Elle est conçue pour prendre en charge les agents, les pipelines RAG et autres applications LLM.
Avantages :
- Open source (Github), et construite sur OpenTelemetry
- Peut être auto-hébergée, accessible via le cloud, ou exécutée directement dans un notebook
- Fournit une intégration Mistral pour tracer automatiquement les appels Client.chat et Agent.chat
- Plateforme analytique robuste, avec un agent copilot pour aider à déboguer votre application
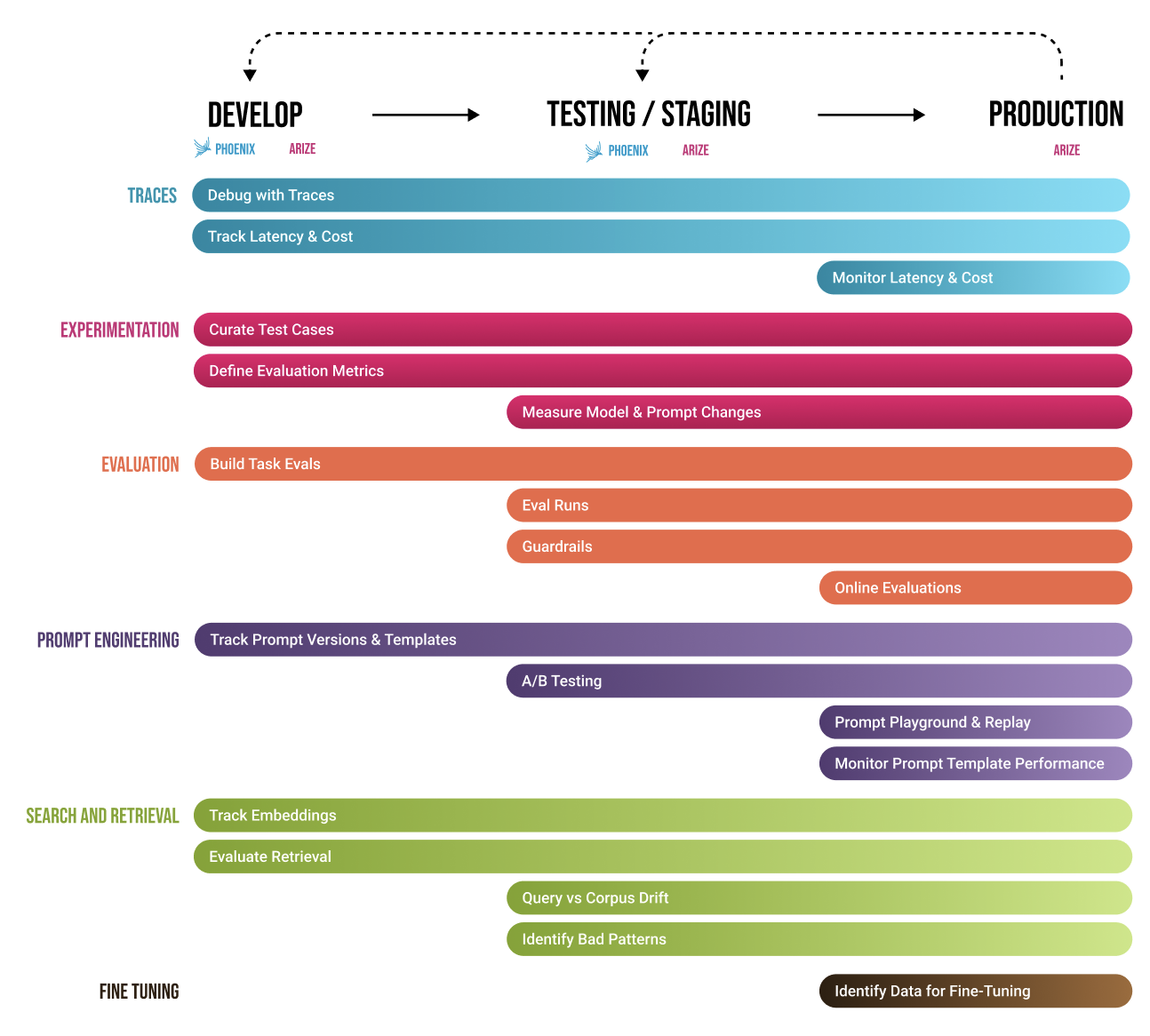
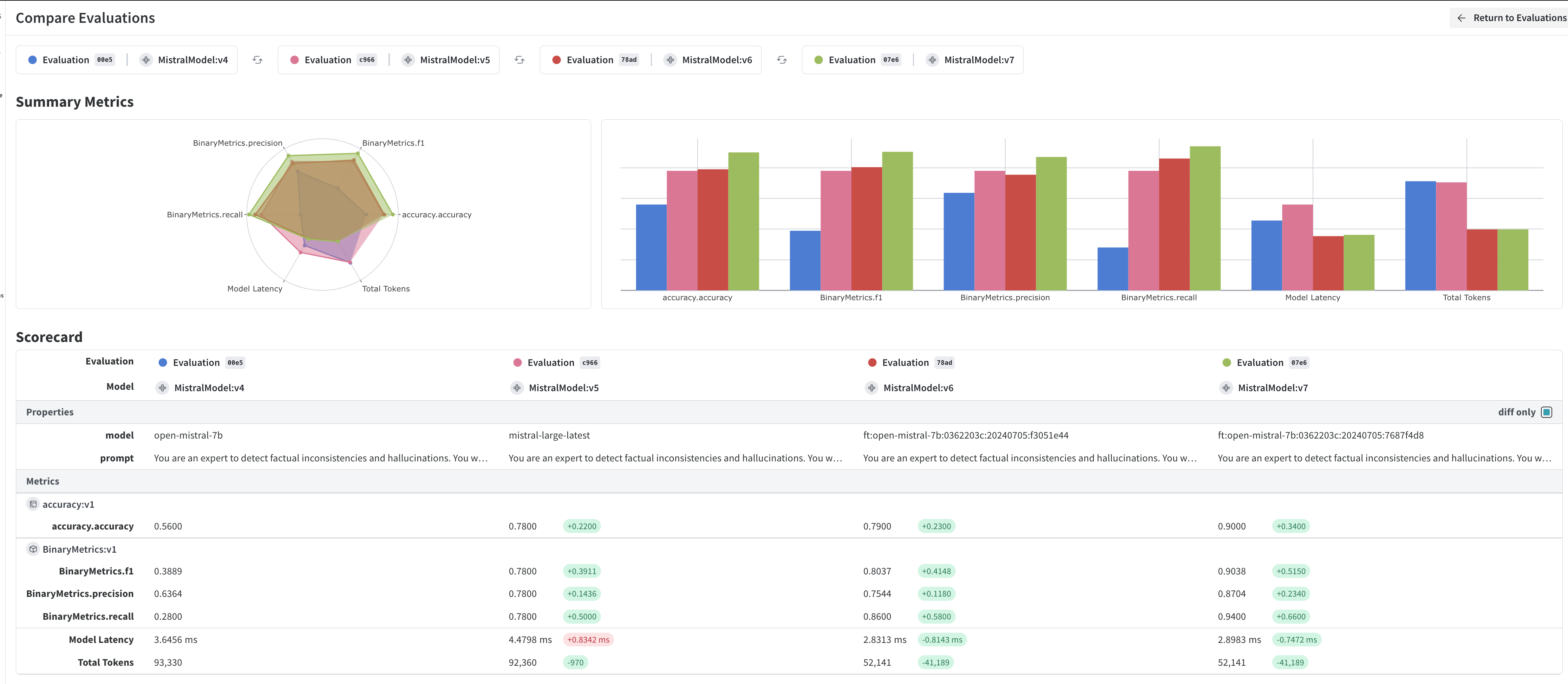
Exemple d'intégration Mistral : Voici un exemple de notebook qui montre comment tracer les appels chat.complete et tool de Mistral dans Phoenix.
Intégration avec Weights and Biases
Weights & Biases est une plateforme complète pour les développeurs IA, dédiée aux workflows ML et LLM. Utilisez W&B Weave pour évaluer, observer et itérer des applications GenAI, et W&B Models comme référentiel pour entraîner et gérer des modèles d’IA.
Avantages :
- Plateforme pour le développement d’apps LLM et workflows ML
- Intégration avec Mistral API
- Mise en route en ajoutant une seule ligne :
weave.init('my-project') - Suit automatiquement entrées, sorties, contexte, erreurs, métriques d’évaluation et traces
- Mise en route en ajoutant une seule ligne :
Exemple d’intégration Mistral :
Pour démarrer, consultez le cookbook.
Intégration avec PromptLayer
PromptLayer est une plateforme de gestion de prompts, de collaboration, de monitoring et d'évaluation. Adaptée aussi bien aux hackers qu'aux équipes en production.
Avantages :
- CMS sans code pour la gestion et le versioning des prompts
- Support natif de Mistral
- Prompts agnostiques au modèle par défaut
- Suivi et observabilité simples des prompts
Intégration Mistral :
Intégration avec AgentOps
AgentOps est une plateforme open source d'observabilité et d'outils de développement pour les agents IA. Elle aide les développeurs à construire, évaluer et surveiller leurs agents IA.
Avantages :
- Open source
- Conçu pour l'observation d'agents
- Permet le voyage dans le temps
- S'intègre avec CrewAI, AutoGen et LangChain
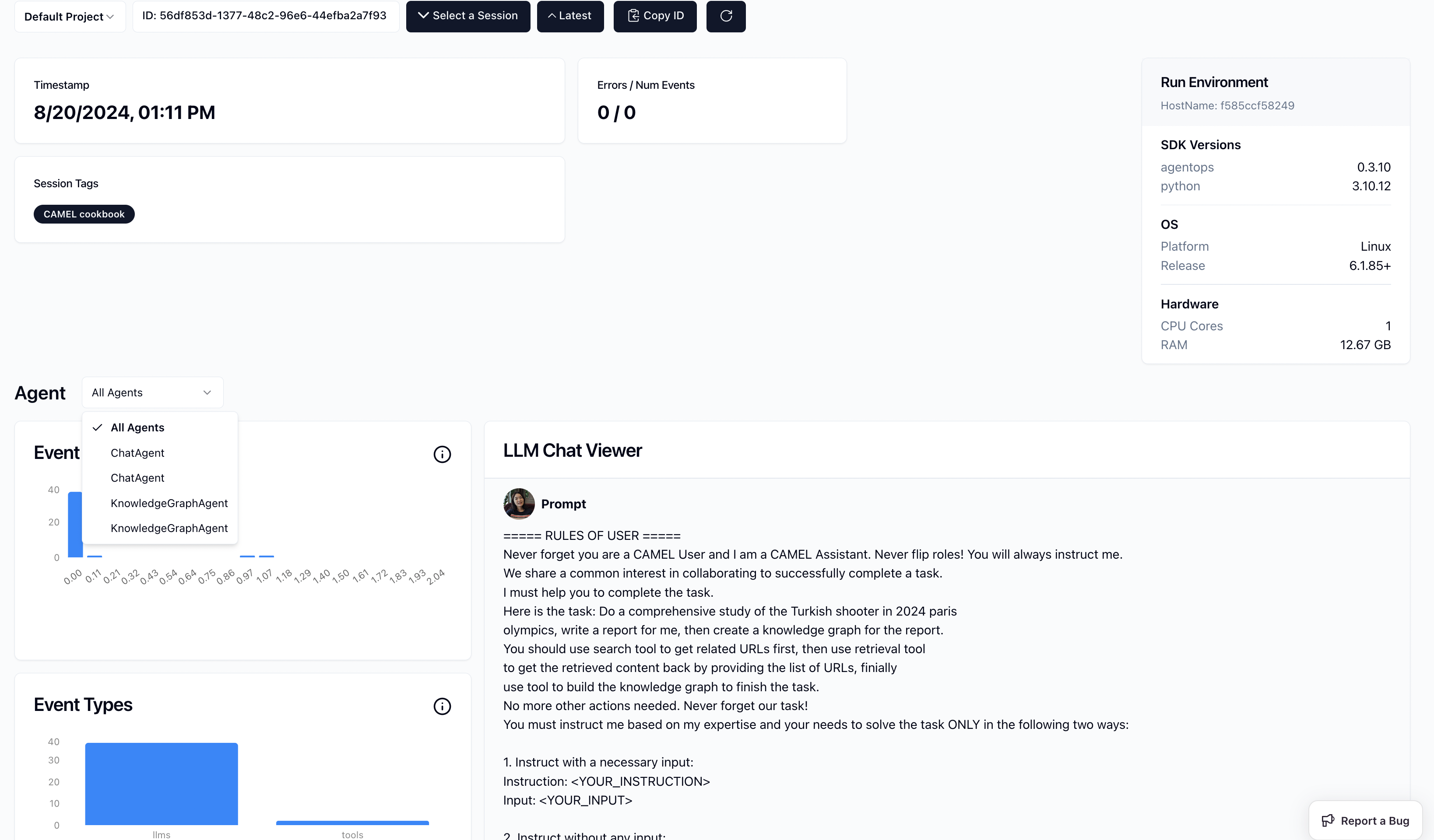
Exemple d'intégration Mistral :
https://github.com/mistralai/cookbook/blob/main/third_party/CAMEL_AI/camel_roleplaying_scraper.ipynb
Intégration avec phospho
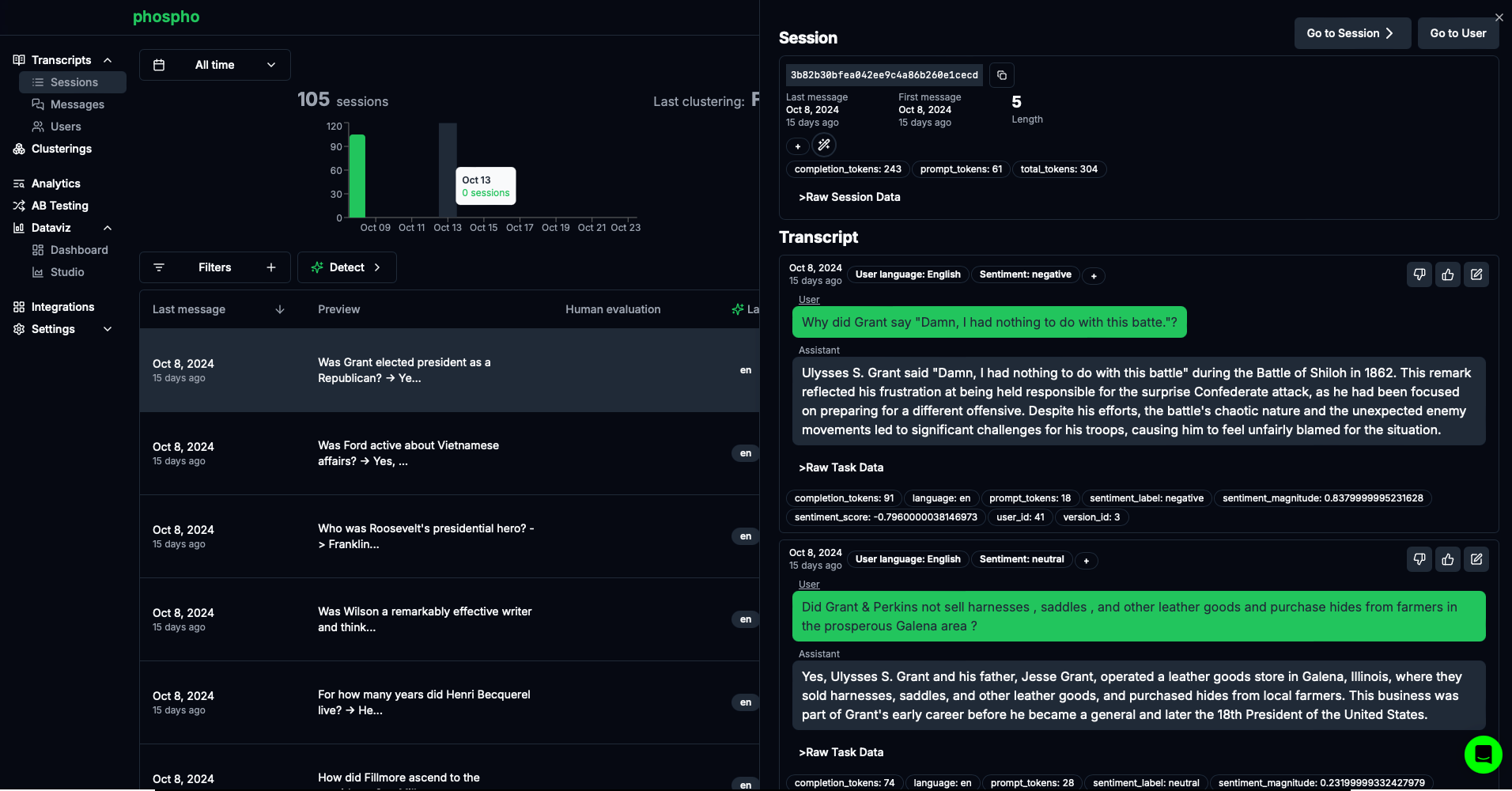
phospho est une plateforme d'analytics de texte qui facilite l'obtention de réponses, la prise de décisions et la réduction du churn par l'exploration de données des messages utilisateurs.
Avantages :
- Plateforme open source (github)
- Clustering et analytics sans code
- Tableaux de bord personnalisables
- Nombreuses intégrations avec d'autres frameworks d'observabilité, langages, API…
Exemple d'intégration Mistral :
- Consultez les notebooks phospho dans le cookbook Mistral.
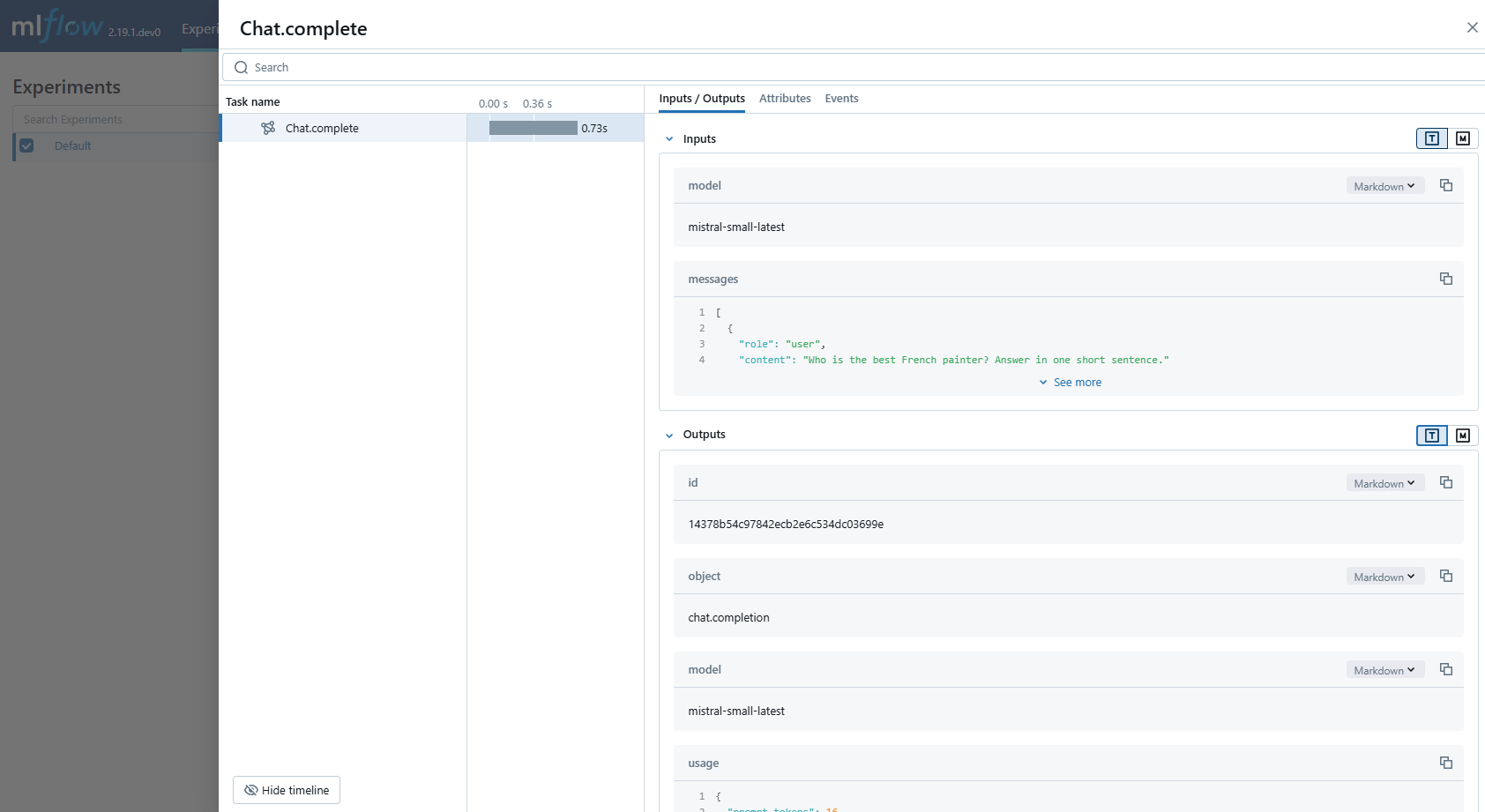
Intégration avec MLflow
MLflow est une plateforme MLOps open source unifiée et de bout en bout pour les applications ML traditionnelles et GenAI, offrant des capacités de traçage complètes pour surveiller et analyser l'exécution des applications GenAI.
Avantages :
- Open source (Github)
- Ajoutez l'intégration Mistral en une seule ligne :
mlflow.mistral.autolog()et obtenez le traçage complet des appels de chat et d'embedding. - Peut être exécuté localement ou auto-hébergé, ou utilisé via l'un des services MLflow managés disponibles
- Fournit des capacités complètes d'évaluation, de versioning et de déploiement de modèles, en plus du traçage et du suivi d'expérimentations.
Exemple d'intégration Mistral : Voici un exemple de notebook.
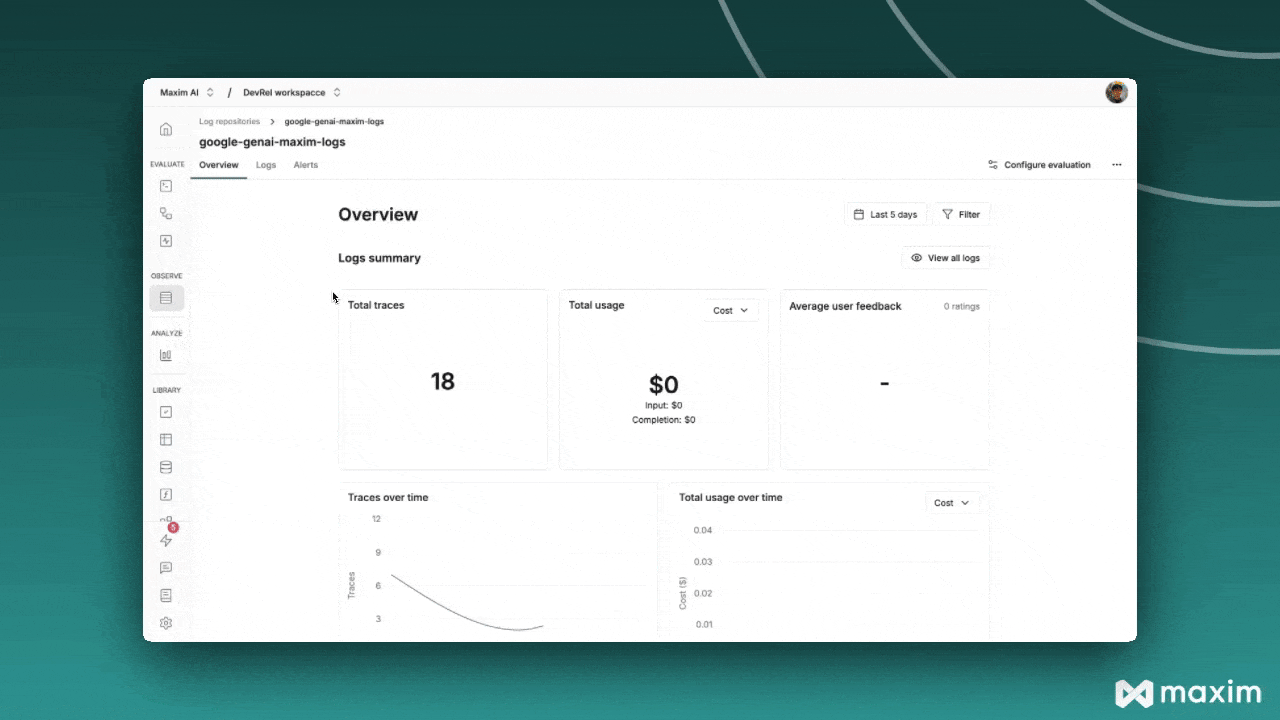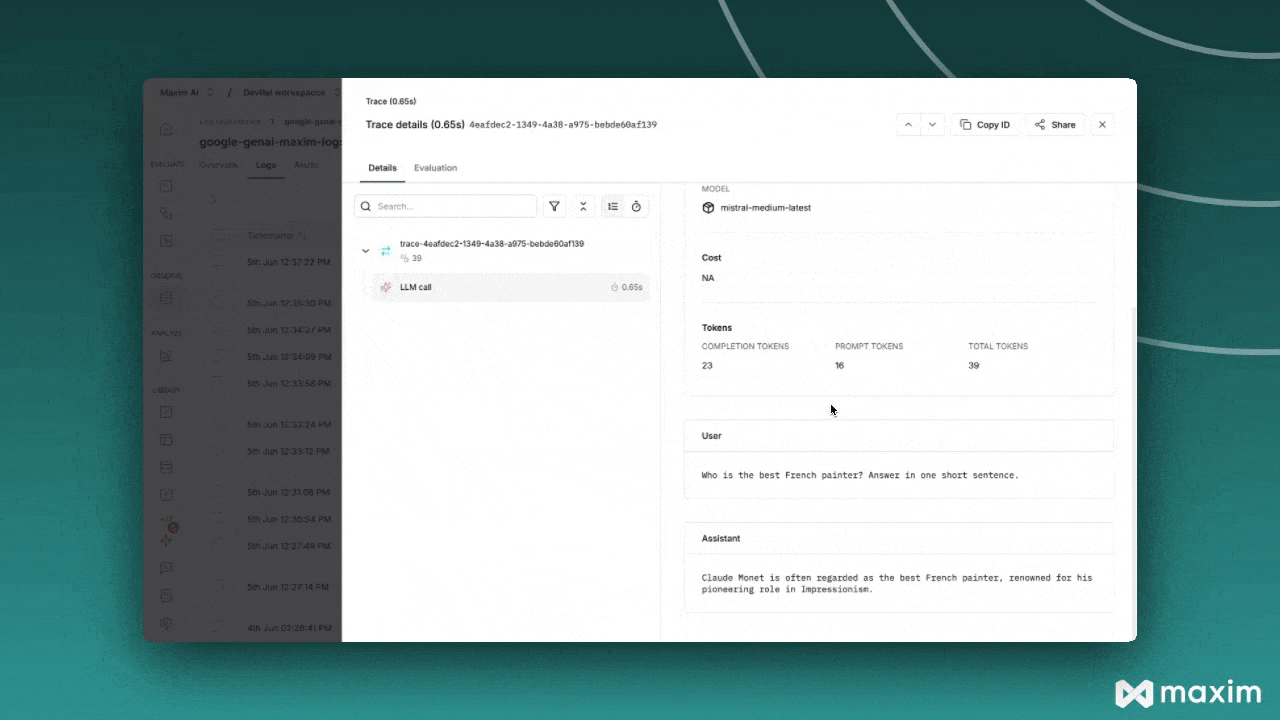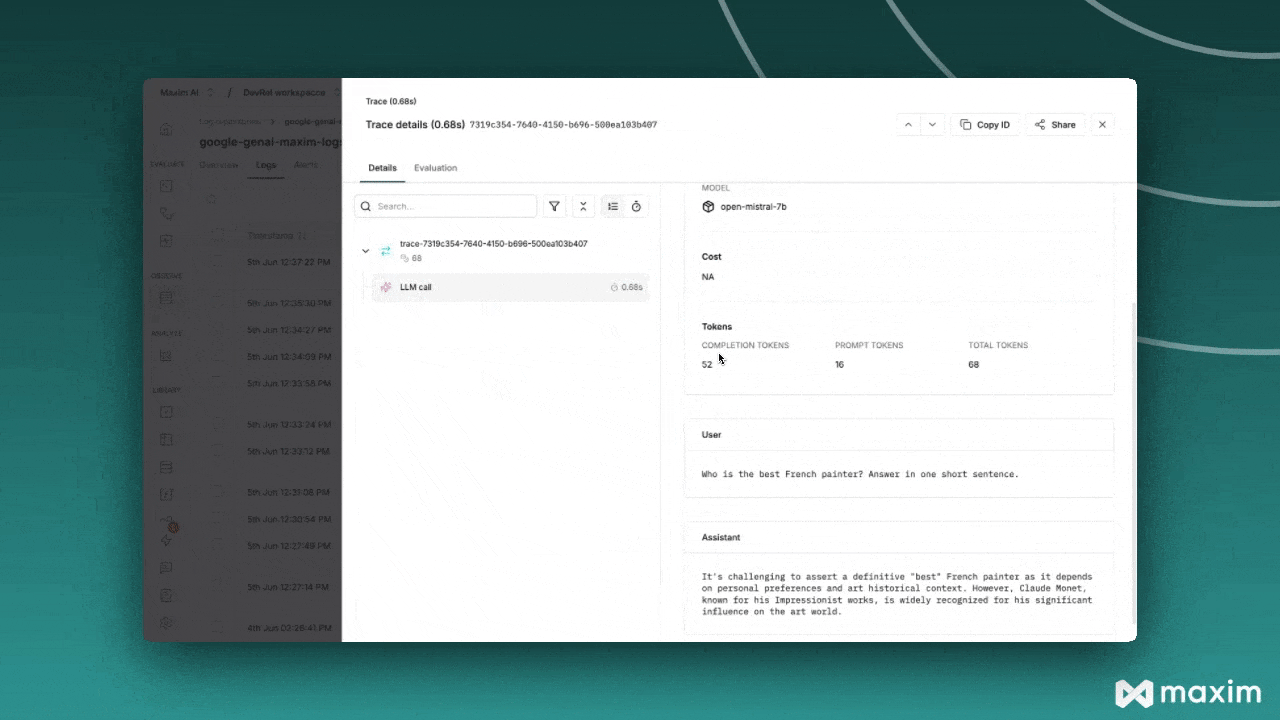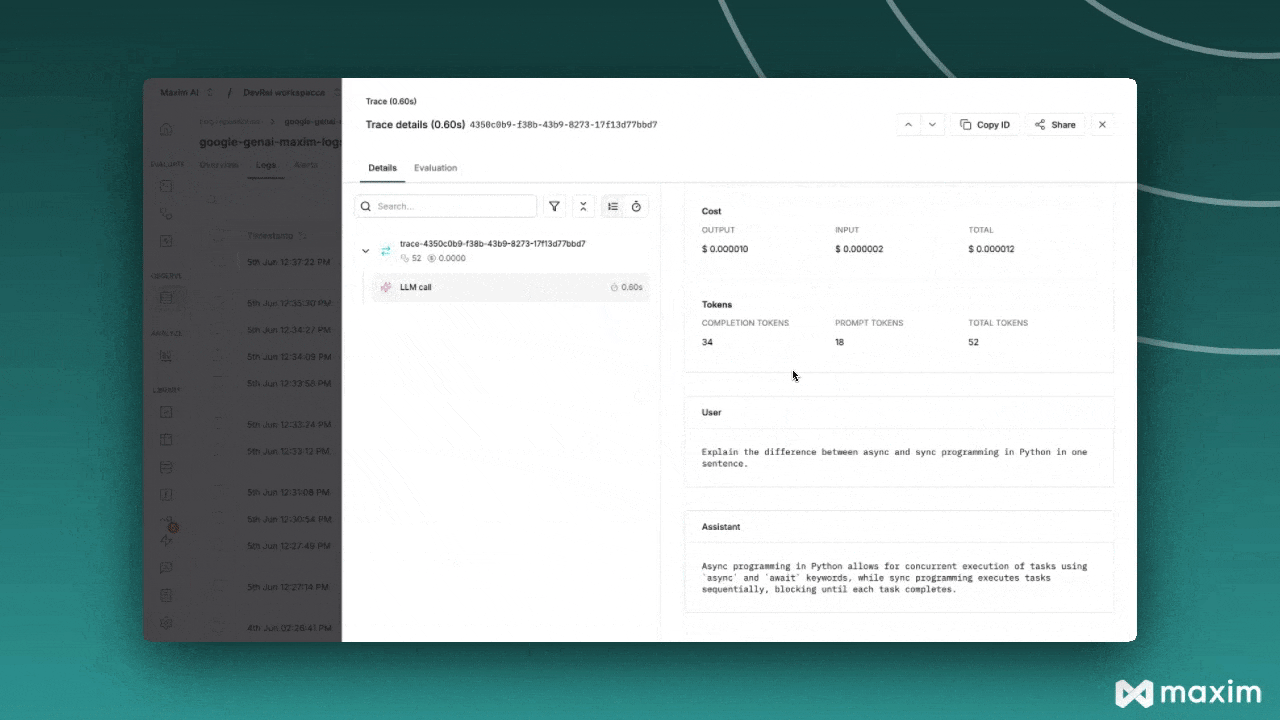
Intégration avec Maxim
Maxim AI offre une observabilité complète pour vos applications IA basées sur Mistral. Avec l'intégration en une ligne de Maxim, vous pouvez facilement tracer et analyser les appels LLM, les métriques et plus encore.
Avantages :
- Analyse de performance : suivez la latence, les tokens consommés et les coûts
- Visualisation avancée : comprenez les trajectoires des agents grâce à des tableaux de bord intuitifs
Exemple d'intégration Mistral :
- Découvrez comment intégrer l'observabilité Maxim avec le SDK Mistral en une seule ligne de code - Notebook Colab
Documentation Maxim pour utiliser Mistral comme fournisseur LLM et Maxim comme logger - Lien vers la documentation