Bibliothèques
Les Bibliothèques sont des bases de connaissances persistantes que vous pouvez remplir avec des documents et connecter à vos agents pour une génération enrichie par récupération (RAG) intégrée. Téléchargez des PDF, des articles ou tout autre document, et vos agents pourront les rechercher à la demande.
Cette page explique comment créer des Bibliothèques, télécharger des documents, vérifier l'état du traitement et contrôler l'accès — le tout via l'API.
Vous pouvez également utiliser les Bibliothèques créées dans Vibe : l'ID de la Bibliothèque est visible dans l'URL (https://chat.mistral.ai/libraries/<library_id>). Pour qu'un agent accède à une Bibliothèque Vibe, vous devez être admin Org et la partager avec l'Organisation. L'inverse fonctionne aussi : créez une Bibliothèque via l'API et partagez-la avec votre équipe dans Vibe.
Créer une Bibliothèque
Créez une nouvelle Bibliothèque en fournissant un nom et une description facultative.
new_library = client.beta.libraries.create(name="Mistral Models", description="A simple library with information about Mistral models.")La réponse inclut des métadonnées comme generated_name et generated_description — celles-ci sont mises à jour automatiquement lorsque vous ajoutez des fichiers.
Une nouvelle Bibliothèque commence vide. Vous pouvez lister ses documents pour le confirmer :
doc_list = client.beta.libraries.documents.list(library_id=new_library.id).data
for doc in doc_list:
print(f"{doc.name}: {doc.extension} with {doc.number_of_pages} pages.")
print(f"{doc.summary}")Lister les Bibliothèques
Listez toutes les Bibliothèques de votre espace de travail ainsi que le nombre de documents qu'elles contiennent.
libraries = client.beta.libraries.list().data
for library in libraries:
print(library.name, f"with {library.nb_documents} documents.")Téléchargement de documents
Téléchargez un document en fournissant l'ID de la Bibliothèque et le fichier.
from mistralai.client.models import File
# Upload document
file_path = "mistral7b.pdf"
with open(file_path, "rb") as file_content:
uploaded_doc = client.beta.libraries.documents.upload(
library_id=new_library.id,
file=File(fileName="mistral7b.pdf", content=file_content),
)Lister les documents
Lista les documents d'une Bibliothèque spécifique :
if len(libraries) == 0:
print("No libraries found.")
else:
doc_list = client.beta.libraries.documents.list(library_id=libraries[0].id).data
for doc in doc_list:
print(f"{doc.name}: {doc.extension} with {doc.number_of_pages} pages.")
print(f"{doc.summary}")État du document
Après avoir téléchargé un document, vous pouvez vérifier son état de traitement.
# Check status document
status = client.beta.libraries.documents.status(library_id=new_library.id, document_id=uploaded_doc.id)
print(status)
# Waiting for process to finish
import time
while status.processing_status == "Running":
status = client.beta.libraries.documents.status(library_id=new_library.id, document_id=uploaded_doc.id)
time.sleep(1)
print(status)L'état est Running pendant le traitement du document et Completed une fois qu'il est prêt.
{
"document_id": "424fdcb8-3c11-478c-a651-9637be8b4fc4",
"processing_status": "Running"
}Obtenir les informations du document
Récupérez les métadonnées complètes d'un document une fois le traitement terminé.
# Get document info once processed
uploaded_doc = client.beta.libraries.documents.get(library_id=new_library.id, document_id=uploaded_doc.id)Extraire le contenu d'un document
Extrayez le contenu textuel de tout document dans une Bibliothèque.
extracted_text = client.beta.libraries.documents.text_content(library_id=new_library.id, document_id=uploaded_doc.id)
# There is also extracted_text signed_url and raw signed_url
print(extracted_text)Supprimer des Bibliothèques et des documents
Supprimez des Bibliothèques ou des documents individuels selon vos besoins.
deleted_library = client.beta.libraries.delete(library_id=new_library.id)Contrôler l'accès
Vous pouvez gérer qui a accès à chaque Bibliothèque. Le contrôle d'accès utilise ces paramètres :
org_id— l'ID de votre organisation.level— le niveau d'accès :"Viewer"ou"Editor".share_with_uuid— l'ID de l'entité avec laquelle vous partagez (retrouvez ces ID dans votre console et les paramètres de la plateforme).share_with_type— le type d'entité :"User","Workspace"ou"Org".
Quelques règles :
- Vous devez être le propriétaire de la Bibliothèque pour la partager.
- Un propriétaire ne peut pas supprimer son propre accès.
- Vous devez être le propriétaire de la Bibliothèque pour supprimer l'accès de quelqu'un d'autre.
- LesVisionneurs ne peuvent pas modifier les Bibliothèques. Les Éditeurs le peuvent.
Étant donnée une bibliothèque, listez toutes les entités ayant accès ainsi que leur niveau d’accès.
accesses_list = client.beta.libraries.accesses.list(library_id=new_library.id)Pour plus de détails sur l'API, voir la référence de l'API Bibliothèques.
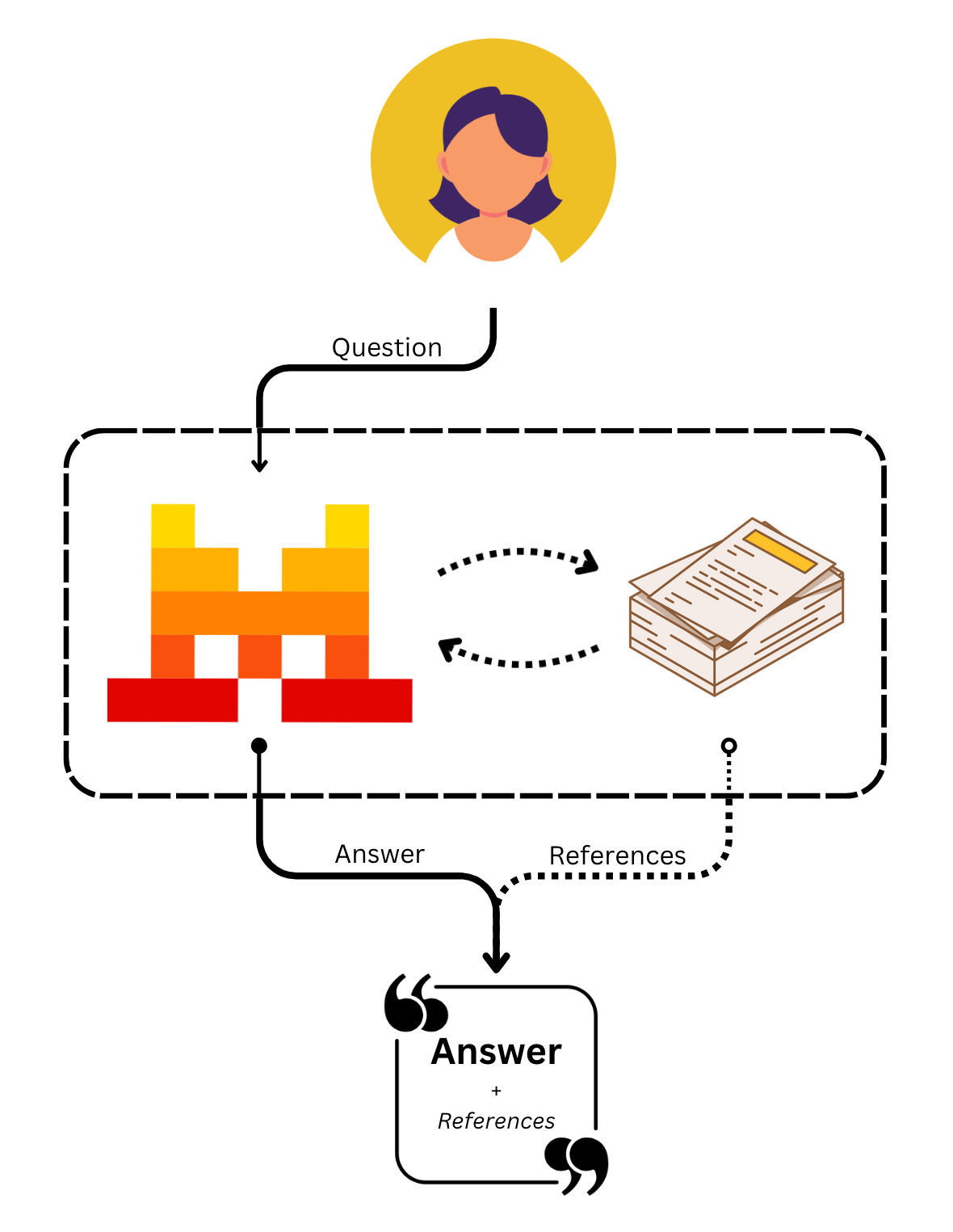
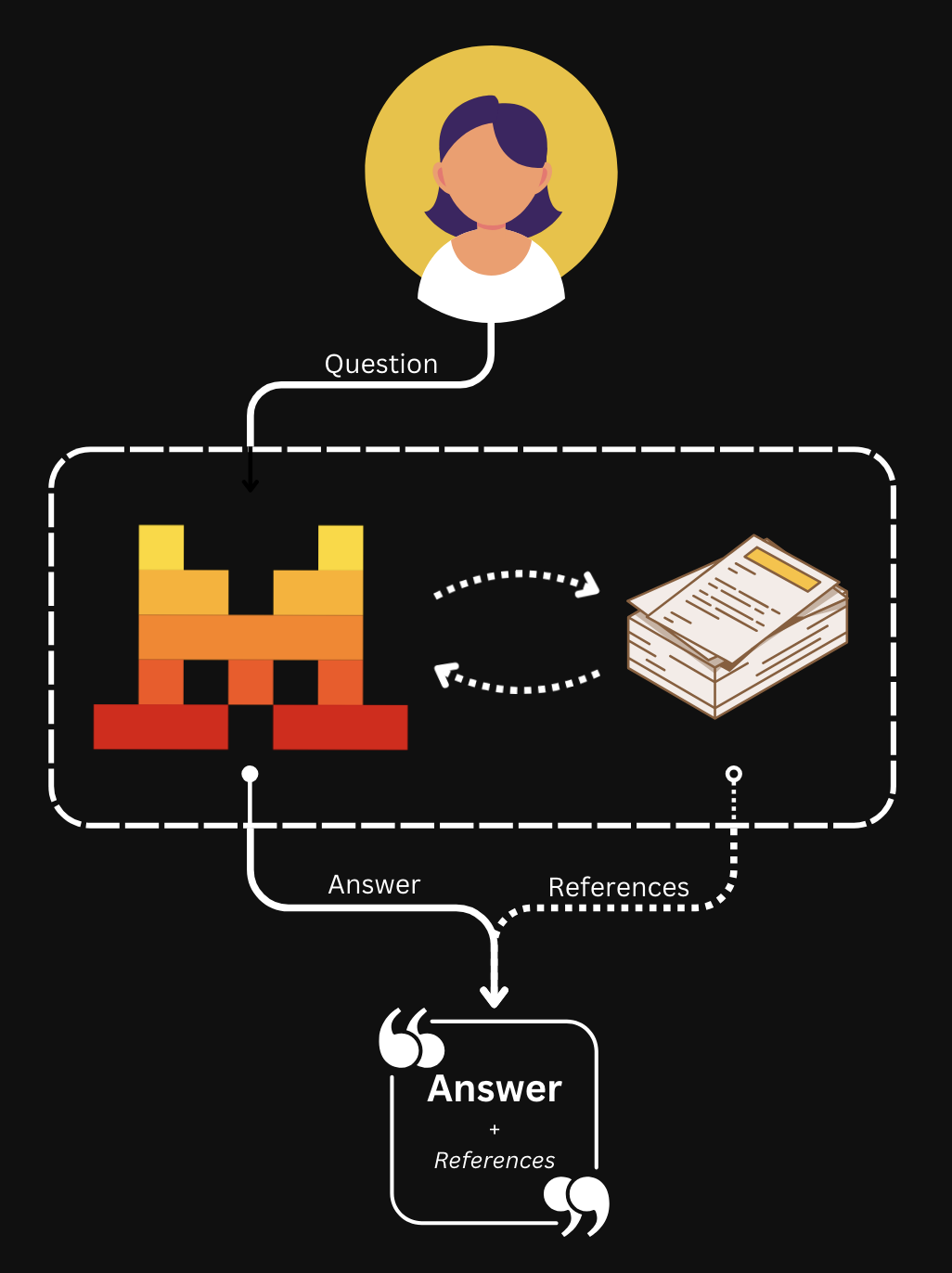
Connecter des Bibliothèques à des agents
Bibliothèque de documents est un outil d’agent intégré qui permet aux agents de rechercher dans vos Bibliothèques. Pour l'utiliser, créez un agent avec l'outil document_library et passez les library_ids auxquels il doit accéder.
library_agent = client.beta.agents.create(
model="mistral-medium-latest",
name="Document Library Agent",
description="Agent used to access documents from the document library.",
instructions="Use the library tool to access external documents.",
tools=[{"type": "document_library", "library_ids": [new_library.id]}],
completion_args={
"temperature": 0.3,
"top_p": 0.95,
}
)Lorsque vous créez un agent, la réponse inclut un ID d'agent. Utilisez-le pour démarrer une conversation.
Conversations avec un agent de Bibliothèque de documents
Une fois votre agent prêt, vous pouvez interroger votre Bibliothèque à tout moment :
response = client.beta.conversations.start(
agent_id=library_agent.id,
inputs="How does the vision encoder for pixtral 12b work"
)Comprendre la réponse
La réponse contient deux types d'entrées :
-
tool.execution— l'outil Bibliothèque de documents a effectué une recherche. Inclutname, des horodatages (created_at,completed_at) et un identifiant uniqueid. -
message.output— la réponse de l'agent, basée sur les documents trouvés. Le champcontentest une liste de fragments qui peuvent être de typetext(la réponse proprement dite) outool_reference(citations renvoyant aux documents sources). Les citations sont utiles pour des résultats vérifiables et traçables.
L'objet usage affiche le nombre de token, y compris les connector_tokens consommés par la recherche dans la Bibliothèque.
L'outil recherche web utilise également des références. Pour plus d'informations sur les citations, voir le guide des citations.
Aller plus loin
- Guide de démarrage RAG : créez un pipeline de génération enrichie par récupération à partir de zéro.
- Embeddings : générez des embeddings vectoriels pour des pipelines RAG personnalisés.
- Outils d'agent : explorez d'autres outils intégrés comme la recherche web, l'interpréteur de code et la génération d'images.