Document understanding
The Document understanding capability combines OCR with large language model capabilities to enable natural language interaction with document content. This allows you to extract information and insights from documents by asking questions in natural language.
The workflow consists of two main steps:
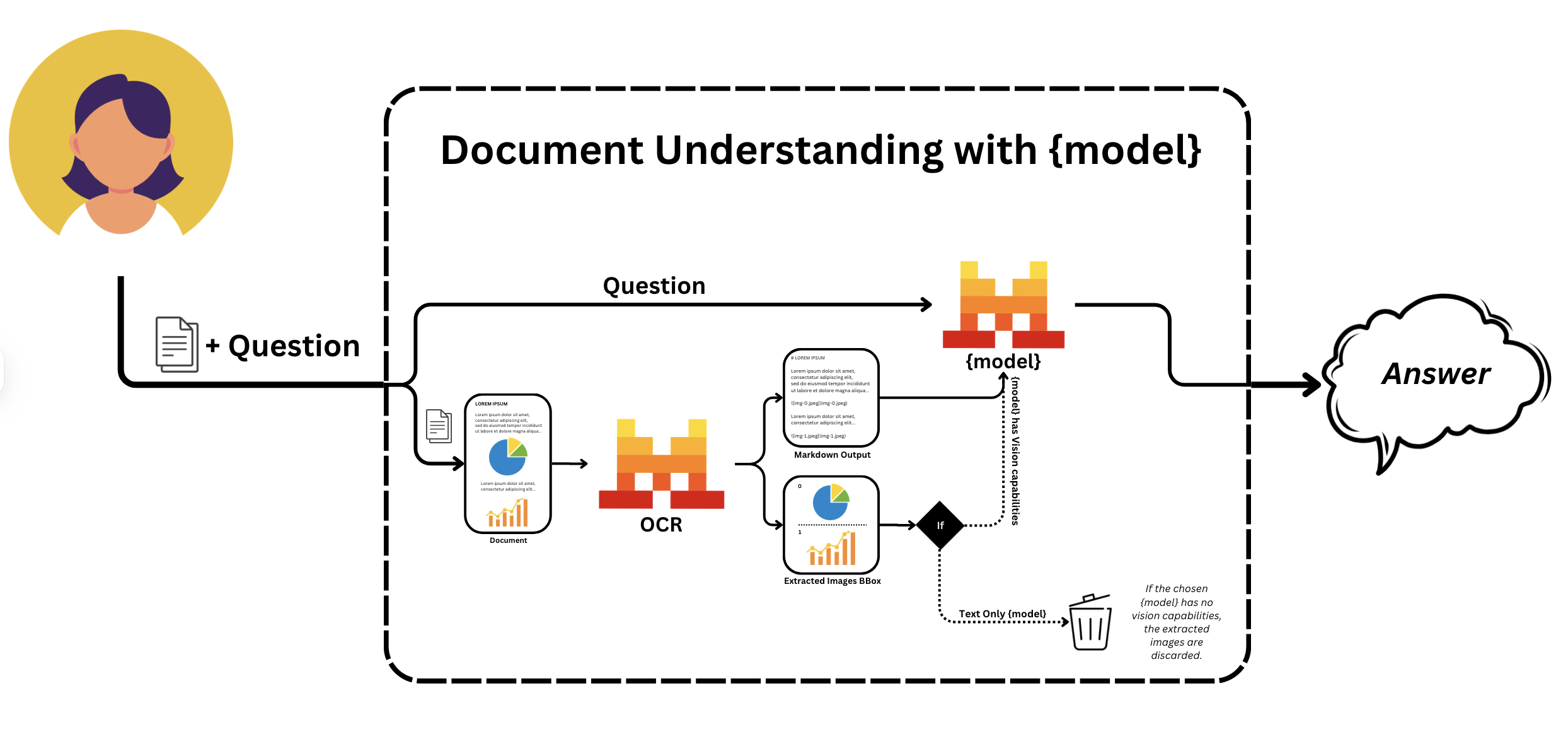
-
Document Processing: OCR extracts text, structure, and formatting, creating a machine-readable version of the document.
-
Language Model Understanding: The extracted document content is analyzed by a large language model. You can ask questions or request information in natural language. The model understands context and relationships within the document and can provide relevant answers based on the document content.
Key capabilities:
- Question answering about specific document content
- Information extraction and summarization
- Document analysis and insights
- Multi-document queries and comparisons
- Context-aware responses that consider the full document
Common use cases:
- Analyzing research papers and technical documents
- Extracting information from business documents
- Processing legal documents and contracts
- Building document Q&A applications
- Automating document-based workflows
The examples below show how to interact with a PDF document using natural language:
- python
- typescript
- curl
import os
from mistralai import Mistral
# Retrieve the API key from environment variables
api_key = os.environ["MISTRAL_API_KEY"]
# Specify model
model = "mistral-small-latest"
# Initialize the Mistral client
client = Mistral(api_key=api_key)
# If local document, upload and retrieve the signed url
# uploaded_pdf = client.files.upload(
# file={
# "file_name": "uploaded_file.pdf",
# "content": open("uploaded_file.pdf", "rb"),
# },
# purpose="ocr"
# )
# signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
# Define the messages for the chat
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "what is the last sentence in the document"
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/1805.04770"
# "document_url": signed_url.url
}
]
}
]
# Get the chat response
chat_response = client.chat.complete(
model=model,
messages=messages
)
# Print the content of the response
print(chat_response.choices[0].message.content)
# Output:
# The last sentence in the document is:\n\n\"Zaremba, W., Sutskever, I., and Vinyals, O. Recurrent neural network regularization. arXiv:1409.2329, 2014.
import { Mistral } from "@mistralai/mistralai";
// import fs from 'fs';
// Retrieve the API key from environment variables
const apiKey = process.env["MISTRAL_API_KEY"];
const client = new Mistral({
apiKey: apiKey,
});
// If local document, upload and retrieve the signed url
// const uploaded_file = fs.readFileSync('uploaded_file.pdf');
// const uploaded_pdf = await client.files.upload({
// file: {
// fileName: "uploaded_file.pdf",
// content: uploaded_file,
// },
// purpose: "ocr"
// });
// const signedUrl = await client.files.getSignedUrl({
// fileId: uploaded_pdf.id,
// });
const chatResponse = await client.chat.complete({
model: "mistral-small-latest",
messages: [
{
role: "user",
content: [
{
type: "text",
text: "what is the last sentence in the document",
},
{
type: "document_url",
documentUrl: "https://arxiv.org/pdf/1805.04770",
// documentUrl: signedUrl.url
},
],
},
],
});
console.log("JSON:", chatResponse.choices[0].message.content);
curl https://api.mistral.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MISTRAL_API_KEY}" \
-d '{
"model": "mistral-small-latest",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "what is the last sentence in the document"
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/1805.04770"
}
]
}
],
"document_image_limit": 8,
"document_page_limit": 64
}'
Cookbooks
For more information on how to make use of Document Understanding, we have the following Document Understanding Cookbook with a simple example.
FAQ
Q: Are there any limits regarding the Document Understanding API?
A: Yes, there are certain limitations for the Document Understanding API. Uploaded document files must not exceed 50 MB in size and should be no longer than 1,000 pages.