Document Library
Document Library is a built-in connector tool that enables agents to access documents from Mistral Cloud.
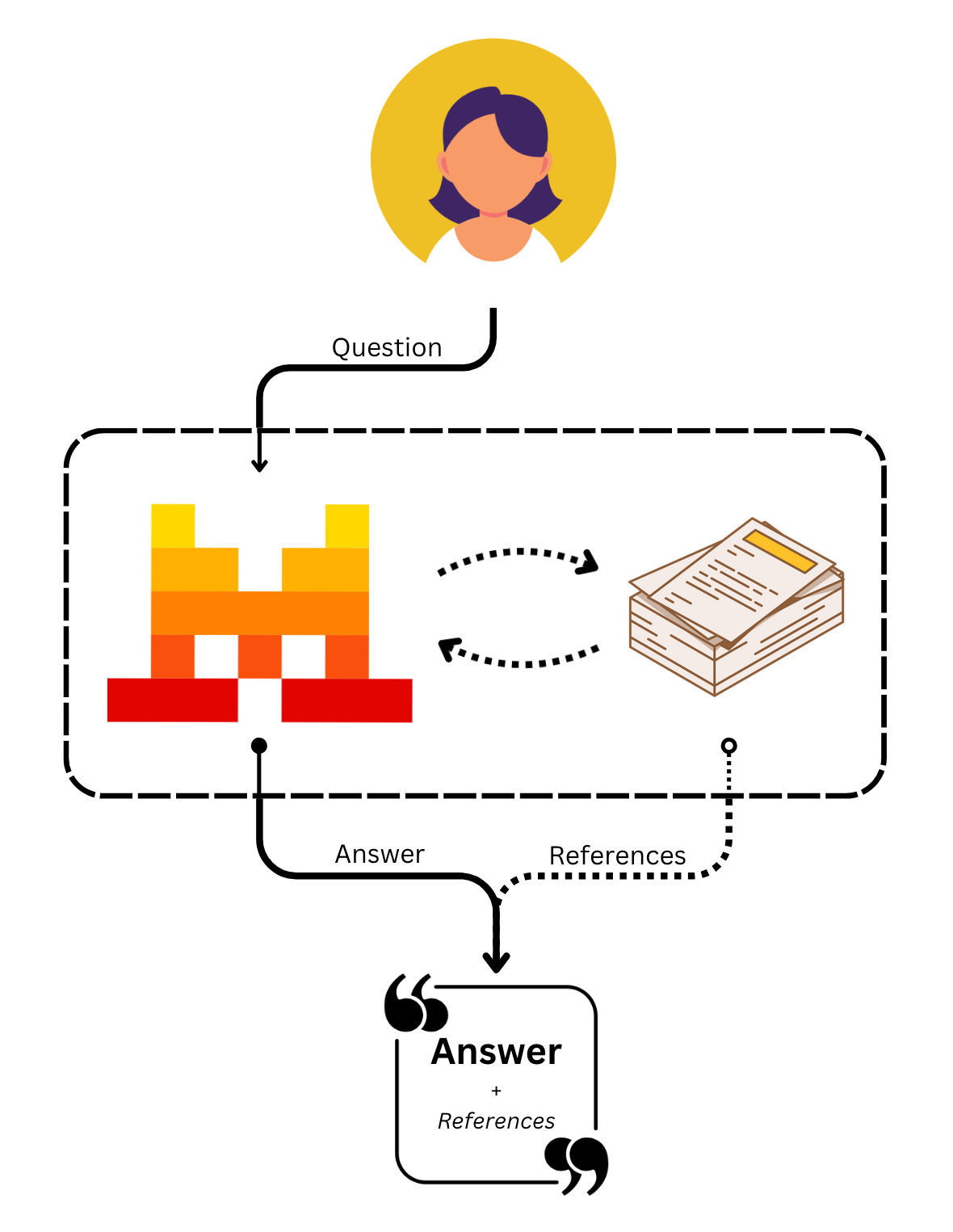
It is a built-in RAG capability that enhances your agents' knowledge with the data you have uploaded.
Manage Libraries
You can manage your libraries using the Mistral AI API, we recommend taking a look at the API spec for the details. Below are some examples of how to interact with libraries and documents.
Listing Libraries
You can list your existing libraries and their documents.
- python
- typescript
- curl
libraries = client.beta.libraries.list().data
for library in libraries:
print(library.name, f"with {library.nb_documents} documents.")
let libraries = await client.beta.libraries.list();
for (const library of libraries.data)
{
console.log(`${library.name} with ${library.nbDocuments} documents`);
}
curl --location "https://api.mistral.ai/v1/libraries" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
Output
X's Library with 152 documents.
My new API library with 1 documents.
Mistral Documentation with 81 documents.
Y's PDFs with 21 documents.
Papers with 2 documents.
Listing Documents in a Library
To list documents in a specific library:
- python
- typescript
- curl
if len(libraries) == 0:
print("No libraries found.")
else:
doc_list = client.beta.libraries.documents.list(library_id=libraries[0].id).data
for doc in doc_list:
print(f"{doc.name}: {doc.extension} with {doc.number_of_pages} pages.")
print(f"{doc.summary}")
if (libraries.data.length === 0)
{
console.log("No libraries found.");
}
else
{
const docList = await client.beta.libraries.documents.list({
libraryId: libraries.data[0].id
});
for (const doc of docList.data)
{
console.log(`${doc.name}: ${doc.extension} with ${doc.numberOfPages} pages.`);
console.log(`${doc.summary}`);
}
}
curl --location "https://api.mistral.ai/v1/libraries/<library_id>/documents?page_size=100&page=0&sort_by=created_at&sort_order=desc" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
You can list and search documents in a library if required.
Creating a New Library
You can create and manage new document libraries directly via our API.
- python
- typescript
- curl
new_library = client.beta.libraries.create(name="Mistral Models", description="A simple library with information about Mistral models.")
const newLibrary = await client.beta.libraries.create({
name: "Mistral Models",
description: "A simple library with information about Mistral models."
});
curl --location "https://api.mistral.ai/v1/libraries" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"name": "Mistral Models",
"description": "A simple library with information about Mistral models."
}'
Contents
{
"id": "0197f425-5e85-7353-b8e7-e8b974b9c613",
"name": "Mistral Models",
"created_at": "2025-07-10T11:42:59.230268Z",
"updated_at": "2025-07-10T11:42:59.230268Z",
"owner_id": "6340e568-a546-4c41-9dee-1fbeb80493e1",
"owner_type": "Workspace",
"total_size": 0,
"nb_documents": 0,
"chunk_size": null,
"emoji": null,
"description": "A simple library with information about Mistral models.",
"generated_name": null,
"generated_description": null,
"explicit_user_members_count": null,
"explicit_workspace_members_count": null,
"org_sharing_role": null
}
When generated, the library will contain different kinds of information. This information is updated and generated when files are added. Specifically, generated_name and generated_description will be constantly updated and kept up to date.
Listing Documents in a New Library
Each library, has a set of documents that belongs to it.
- python
- typescript
- curl
doc_list = client.beta.libraries.documents.list(library_id=new_library.id).data
for doc in doc_list:
print(f"{doc.name}: {doc.extension} with {doc.number_of_pages} pages.")
print(f"{doc.summary}")
const docList = await client.beta.libraries.documents.list({ libraryId: newLibrary.id });
for (const doc of docList.data) {
console.log(`${doc.name}: ${doc.extension} with ${doc.numberOfPages} pages.`);
console.log(`${doc.summary}`);
}
curl --location "https://api.mistral.ai/v1/libraries/<library_id>/documents?page_size=100&page=0&sort_by=created_at&sort_order=desc" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
At first, a new library will not have any documents inside.
Uploading a Document
You can upload and remove documents from a library.
Upload
- python
- typescript
- curl
from mistralai.models import File
# Upload document
file_path = "mistral7b.pdf"
with open(file_path, "rb") as file_content:
uploaded_doc = client.beta.libraries.documents.upload(
library_id=new_library.id,
file=File(fileName="mistral7b.pdf", content=file_content),
)
const filePath = "~/path/to/doc.pdf";
const fileContent = fs.readFileSync(filePath);
const uploadedDoc = await client.beta.libraries.documents.upload({
libraryId: newLibrary.id,
requestBody: {
file: {
fileName: "mistral7b.pdf",
content: fileContent
}
}
});
curl --location --request POST "https://api.mistral.ai/v1/libraries/<library_id>/documents" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--header "Content-Type: multipart/form-data" \
--form "file=@mistral7b.pdf;type=application/pdf"
Content
{
"id": "424fdcb8-3c11-478c-a651-9637be8b4fc4",
"library_id": "0197f425-5e85-7353-b8e7-e8b974b9c613",
"hash": "8ad11d7d6d3a9ce8a0870088ebbcdb00",
"mime_type": "application/pdf",
"extension": "pdf",
"size": 3749788,
"name": "mistral7b.pdf",
"created_at": "2025-07-10T11:43:01.017430Z",
"processing_status": "Running",
"uploaded_by_id": "6340e568-a546-4c41-9dee-1fbeb80493e1",
"uploaded_by_type": "Workspace",
"tokens_processing_total": 0,
"summary": null,
"last_processed_at": null,
"number_of_pages": null,
"tokens_processing_main_content": null,
"tokens_processing_summary": null
}
Status
- python
- typescript
- curl
# Check status document
status = client.beta.libraries.documents.status(library_id=new_library.id, document_id=uploaded_doc.id)
print(status)
# Waiting for process to finish
import time
while status.processing_status == "Running":
status = client.beta.libraries.documents.status(library_id=new_library.id, document_id=uploaded_doc.id)
time.sleep(1)
print(status)
// Check status document
const docStatus = await client.beta.libraries.documents.status({
libraryId: newLibrary.id,
documentId: uploadedDoc.id
});
console.log(docStatus);
// Waiting for process to finish
while (docStatus.processingStatus === "Running") {
await new Promise(resolve => setTimeout(resolve, 1000)); // Wait for 1 second
const updatedStatus = await client.beta.libraries.documents.status({
libraryId: newLibrary.id,
documentId: uploadedDoc.id
});
console.log(updatedStatus);
Object.assign(docStatus, updatedStatus); // Update the status object
}
console.log(docStatus);
curl --location "https://api.mistral.ai/v1/libraries/<library_id>/documents/<document_id>/status" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
Contents
Running Status
{
"document_id": "424fdcb8-3c11-478c-a651-9637be8b4fc4",
"processing_status": "Running"
}
Finished Status
{
"document_id": "2445a837-8f4e-475f-8183-fe4e99fed2d9",
"processing_status": "Completed"
}
Get Document
- python
- typescript
- curl
# Get document info once processed
uploaded_doc = client.beta.libraries.documents.get(library_id=new_library.id, document_id=uploaded_doc.id)
// Get document info once processed
const processedDoc = await client.beta.libraries.documents.get({
libraryId: newLibrary.id,
documentId: uploadedDoc.id
});
curl --location "https://api.mistral.ai/v1/libraries/<library_id>/documents/<document_id>" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
Contents
{
"id": "424fdcb8-3c11-478c-a651-9637be8b4fc4",
"library_id": "0197f425-5e85-7353-b8e7-e8b974b9c613",
"hash": "8ad11d7d6d3a9ce8a0870088ebbcdb00",
"mime_type": "application/pdf",
"extension": "pdf",
"size": 3749788,
"name": "mistral7b.pdf",
"created_at": "2025-07-10T11:43:01.017430Z",
"processing_status": "Completed",
"uploaded_by_id": "6340e568-a546-4c41-9dee-1fbeb80493e1",
"uploaded_by_type": "Workspace",
"tokens_processing_total": 17143,
"summary": "Mistral 7B is a 7-billion-parameter language model that outperforms larger models like Llama 2 and Llama 1 in various benchmarks, including reasoning, mathematics, and code generation. It uses grouped-query attention (GQA) for faster inference and sliding window attention (SWA) to handle longer sequences efficiently. The model is released under the Apache 2.0 license and includes a fine-tuned instruction-following version, Mistral 7B - Instruct, which surpasses Llama 2 13B - Chat in performance. The document also details the model's architecture, results, and applications, including content moderation and guardrails for safe usage.",
"last_processed_at": "2025-07-10T11:43:09.604284Z",
"number_of_pages": 9,
"tokens_processing_main_content": 8436,
"tokens_processing_summary": 8707
}
Extracting Text from a Document
You can extract text from any document that belongs to a library.
- python
- typescript
- curl
extracted_text = client.beta.libraries.documents.text_content(library_id=new_library.id, document_id=uploaded_doc.id)
# There is also extracted_text signed_url and raw signed_url
print(extracted_text)
const extractedText = await client.beta.libraries.documents.textContent({
libraryId: newLibrary.id,
documentId: uploadedDoc.id
});
console.log(extractedText);
curl --location "https://api.mistral.ai/v1/libraries/<library_id>/documents/<document_id>/text_content" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
Output
{
"text": "# Mistral 7B \n\nAlbert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed\n\n\n\n## Abstract\n\nWe introduce Mistral 7B, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms the best open 13B model (Llama 2) across all evaluated benchmarks, and the best released 34B model (Llama 1) in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B - Instruct, that surpasses Llama 213B - chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license. Code: https://github.com/mistralai/mistral-src Webpage: https://mistral.ai/news/announcing-mistral-7b/\n\n## 1 Introduction\n\nIn the rapidly evolving domain of Natural Language Processing (NLP), the race towards higher model performance often necessitates an escalation in model size. However, this scaling tends to increase computational costs and inference latency, thereby raising barriers to deployment in practical, real-world scenarios. In this context, the search for balanced models delivering both high-level performance and efficiency becomes critically essential. Our model, Mistral 7B, demonstrates that a carefully designed language model can deliver high performance while maintaining an efficient inference. Mistral 7B outperforms the previous best 13B model (Llama 2, [26]) across all tested benchmarks, and surpasses the best 34B model (LLaMa 34B, [25]) in mathematics and code generation. Furthermore, Mistral 7B approaches the coding performance of Code-Llama 7B [20], without sacrificing performance on non-code related benchmarks.\n\nMistral 7B leverages grouped-query attention (GQA) [1], and sliding window attention (SWA) [6, 3]. GQA significantly accelerates the inference speed, and also reduces the memory requirement during decoding, allowing for higher batch sizes hence higher throughput, a crucial factor for real-time applications. In addition, SWA is designed to handle longer sequences more effectively at a reduced computational cost, thereby alleviating a common limitation in LLMs. These attention mechanisms collectively contribute to the enhanced performance and efficiency of Mistral 7B.Mistral 7B is released under the Apache 2.0 license. This release is accompanied by a reference implementation [1] facilitating easy deployment either locally or on cloud platforms such as AWS, GCP, or Azure using the vLLM [17] inference server and SkyPilot [2]. Integration with Hugging Face [3] is also streamlined for easier integration. Moreover, Mistral 7B is crafted for ease of fine-tuning across a myriad of tasks. As a demonstration of its adaptability and superior performance, we present a chat model fine-tuned from Mistral 7B that significantly outperforms the Llama 2 13B - Chat model.\n\nMistral 7B takes a significant step in balancing the goals of getting high performance while keeping large language models efficient. Through our work, our aim is to help the community create more affordable, efficient, and high-performing language models that can be used in a wide range of real-world applications.\n\n# 2 Architectural details \n\n\n\nFigure 1: Sliding Window Attention. The number of operations in vanilla attention is quadratic in the sequence length, and the memory increases linearly with the number of tokens. At inference time, this incurs higher latency and smaller throughput due to reduced cache availability. To alleviate this issue, we use sliding window attention: each token can attend to at most $W$ tokens from the previous layer (here, $W=3$ ). Note that tokens outside the sliding window still influence next word prediction. At each attention layer, information can move forward by $W$ tokens. Hence, after $k$ attention layers, information can move forward by up to $k \\times W$ tokens.\n\nMistral 7B is based on a transformer architecture [27]. The main parameters of the architecture are summarized in Table 1. Compared to Llama, it introduces a few changes that we summarize below.\n\nSliding Window Attention. SWA exploits the stacked layers of a transformer to attend information beyond the window size $W$. The hidden state in position $i$ of the layer $k, h_{i}$, attends to all hidden states from the previous layer with positions between $i-W$ and $i$. Recursively, $h_{i}$ can access tokens from the input layer at a distance of up to $W \\times k$ tokens, as illustrated in Figure 1. At the last layer, using a window size of $W=4096$, we have a theoretical attention span of approximately $131 K$ tokens. In practice, for a sequence length of 16 K and $W=4096$, changes made to FlashAttention [11] and xFormers [18] yield a 2 x speed improvement over a vanilla attention baseline.\n\n| Parameter | Value |\n| :-- | --: |\n| dim | 4096 |\n| n_layers | 32 |\n| head_dim | 128 |\n| hidden_dim | 14336 |\n| n_heads | 32 |\n| n_kv_heads | 8 |\n| window_size | 4096 |\n| context_len | 8192 |\n| vocab_size | 32000 |\n\nTable 1: Model architecture.\n\nRolling Buffer Cache. A fixed attention span means that we can limit our cache size using a rolling buffer cache. The cache has a fixed size of $W$, and the keys and values for the timestep $i$ are stored in position $i \\bmod W$ of the cache. As a result, when the position $i$ is larger than $W$, past values in the cache are overwritten, and the size of the cache stops increasing. We provide an illustration in Figure 2 for $W=3$. On a sequence length of 32 k tokens, this reduces the cache memory usage by 8 x , without impacting the model quality.\n\n[^0]\n[^0]: ${ }^{1}$ https://github.com/mistralai/mistral-src\n ${ }^{2}$ https://github.com/skypilot-org/skypilot\n ${ }^{3}$ https://huggingface.co/mistralai\n\nFigure 2: Rolling buffer cache. The cache has a fixed size of $W=4$. Keys and values for position $i$ are stored in position $i \\bmod W$ of the cache. When the position $i$ is larger than $W$, past values in the cache are overwritten. The hidden state corresponding to the latest generated tokens are colored in orange.\n\nPre-fill and Chunking. When generating a sequence, we need to predict tokens one-by-one, as each token is conditioned on the previous ones. However, the prompt is known in advance, and we can pre-fill the $(k, v)$ cache with the prompt. If the prompt is very large, we can chunk it into smaller pieces, and pre-fill the cache with each chunk. For this purpose, we can select the window size as our chunk size. For each chunk, we thus need to compute the attention over the cache and over the chunk. Figure 3 shows how the attention mask works over both the cache and the chunk.\n\n\nFigure 3: Pre-fill and chunking. During pre-fill of the cache, long sequences are chunked to limit memory usage. We process a sequence in three chunks, \"The cat sat on\", \"the mat and saw\", \"the dog go to\". The figure shows what happens for the third chunk (\"the dog go to\"): it attends itself using a causal mask (rightmost block), attends the cache using a sliding window (center block), and does not attend to past tokens as they are outside of the sliding window (left block).\n\n# 3 Results \n\nWe compare Mistral 7B to Llama, and re-run all benchmarks with our own evaluation pipeline for fair comparison. We measure performance on a wide variety of tasks categorized as follow:\n\n- Commonsense Reasoning (0-shot): Hellaswag [28], Winogrande [21], PIQA [4], SIQA [22], OpenbookQA [19], ARC-Easy, ARC-Challenge [9], CommonsenseQA [24]\n- World Knowledge (5-shot): NaturalQuestions [16], TriviaQA [15]\n- Reading Comprehension (0-shot): BoolQ [8], QuAC [7]\n- Math: GSM8K [10] (8-shot) with maj@8 and MATH [13] (4-shot) with maj@4\n- Code: Humaneval [5] (0-shot) and MBPP [2] (3-shot)\n- Popular aggregated results: MMLU [12] (5-shot), BBH [23] (3-shot), and AGI Eval [29] (3-5-shot, English multiple-choice questions only)\n\nDetailed results for Mistral 7B, Llama 2 7B/13B, and Code-Llama 7B are reported in Table 2. Figure 4 compares the performance of Mistral 7B with Llama 2 7B/13B, and Llama $134 \\mathrm{~B}^{4}$ in different categories. Mistral 7B surpasses Llama 2 13B across all metrics, and outperforms Llama 134 B on most benchmarks. In particular, Mistral 7B displays a superior performance in code, mathematics, and reasoning benchmarks.\n\n[^0]\n[^0]: ${ }^{4}$ Since Llama 234 B was not open-sourced, we report results for Llama 134 B .\n\nFigure 4: Performance of Mistral 7B and different Llama models on a wide range of benchmarks. All models were re-evaluated on all metrics with our evaluation pipeline for accurate comparison. Mistral 7B significantly outperforms Llama 2 7B and Llama 2 13B on all benchmarks. It is also vastly superior to Llama 1 34B in mathematics, code generation, and reasoning benchmarks.\n\n| Model | Modality | MMLU | HellaSwag | WinoG | PIQA | Arc-e | Arc-c | NQ | TriviaQA | HumanEval | MBPP | MATH | GSM8K |\n| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |\n| LLaMA 2 7B | Pretrained | $44.4 \\%$ | $77.1 \\%$ | $69.5 \\%$ | $77.9 \\%$ | $68.7 \\%$ | $43.2 \\%$ | $24.7 \\%$ | $63.8 \\%$ | $11.6 \\%$ | $26.1 \\%$ | $3.9 \\%$ | $16.0 \\%$ |\n| LLaMA 2 13B | Pretrained | $55.6 \\%$ | $\\mathbf{8 0 . 7 \\%}$ | $72.9 \\%$ | $80.8 \\%$ | $75.2 \\%$ | $48.8 \\%$ | $\\mathbf{2 9 . 0 \\%}$ | $\\mathbf{6 9 . 6 \\%}$ | $18.9 \\%$ | $35.4 \\%$ | $6.0 \\%$ | $34.3 \\%$ |\n| Code-Llama 7B | Finetuned | $36.9 \\%$ | $62.9 \\%$ | $62.3 \\%$ | $72.8 \\%$ | $59.4 \\%$ | $34.5 \\%$ | $11.0 \\%$ | $34.9 \\%$ | $\\mathbf{3 1 . 1 \\%}$ | $\\mathbf{5 2 . 5 \\%}$ | $5.2 \\%$ | $20.8 \\%$ |\n| Mistral 7B | Pretrained | $\\mathbf{6 0 . 1 \\%}$ | $\\mathbf{8 1 . 3 \\%}$ | $\\mathbf{7 5 . 3 \\%}$ | $\\mathbf{8 3 . 0 \\%}$ | $\\mathbf{8 0 . 0 \\%}$ | $\\mathbf{5 5 . 5 \\%}$ | $\\mathbf{2 8 . 8 \\%}$ | $\\mathbf{6 9 . 9 \\%}$ | $\\mathbf{3 0 . 5 \\%}$ | $47.5 \\%$ | $\\mathbf{1 3 . 1 \\%}$ | $\\mathbf{5 2 . 2 \\%}$ |\n\nTable 2: Comparison of Mistral 7B with Llama. Mistral 7B outperforms Llama 2 13B on all metrics, and approaches the code performance of Code-Llama 7B without sacrificing performance on non-code benchmarks.\n\nSize and Efficiency. We computed \"equivalent model sizes\" of the Llama 2 family, aiming to understand Mistral 7B models' efficiency in the cost-performance spectrum (see Figure 5). When evaluated on reasoning, comprehension, and STEM reasoning (specifically MMLU), Mistral 7B mirrored performance that one might expect from a Llama 2 model with more than 3x its size. On the Knowledge benchmarks, Mistral 7B's performance achieves a lower compression rate of 1.9x, which is likely due to its limited parameter count that restricts the amount of knowledge it can store. Evaluation Differences. On some benchmarks, there are some differences between our evaluation protocol and the one reported in the Llama 2 paper: 1) on MBPP, we use the hand-verified subset 2) on TriviaQA, we do not provide Wikipedia contexts.\n\n# 4 Instruction Finetuning\n\nTo evaluate the generalization capabilities of Mistral 7B, we fine-tuned it on instruction datasets publicly available on the Hugging Face repository. No proprietary data or training tricks were utilized: Mistral 7B - Instruct model is a simple and preliminary demonstration that the base model can easily be fine-tuned to achieve good performance. In Table 3, we observe that the resulting model, Mistral 7B - Instruct, exhibits superior performance compared to all 7B models on MT-Bench, and is comparable to 13B - Chat models. An independent human evaluation was conducted on https://llmboxing.com/leaderboard.\n\n| Model | Chatbot Arena\nELO Rating | MT Bench |\n| --- | --- | --- |\n| WizardLM 13B v1.2 | 1047 | 7.2 |\n| Mistral 7B Instruct | $\\mathbf{1 0 3 1}$ | $\\mathbf{6 . 8 4}+\\mathbf{- 0 . 0 7}$ |\n| Llama 2 13B Chat | 1012 | 6.65 |\n| Vicuna 13B | 1041 | 6.57 |\n| Llama 2 7B Chat | 985 | 6.27 |\n| Vicuna 7B | 997 | 6.17 |\n| Alpaca 13B | 914 | 4.53 |\n\nTable 3: Comparison of Chat models. Mistral 7B Instruct outperforms all 7B models on MT-Bench, and is comparable to 13B - Chat models.\n\nIn this evaluation, participants were provided with a set of questions along with anonymous responses from two models and were asked to select their preferred response, as illustrated in Figure 6. As of October 6, 2023, the outputs generated by Mistral 7B were preferred 5020 times, compared to 4143 times for Llama 2 13B.\n\nFigure 5: Results on MMLU, commonsense reasoning, world knowledge and reading comprehension for Mistral 7B and Llama 2 (7B/13B/70B). Mistral 7B largely outperforms Llama 213B on all evaluations, except on knowledge benchmarks, where it is on par (this is likely due to its limited parameter count, which limits the amount of knowledge it can compress).\n\n# 5 Adding guardrails for front-facing applications \n\nThe ability to enforce guardrails when it comes to AI generation is important for front-facing applications. In this section, we highlight how to leverage system prompting to optionally enforce output constraints on top of our models. Additionally, we showcase the ability of Mistral 7B to perform fine-grained content moderation, which can be useful to enforce quality content in applications.\n\n### 5.1 System prompt to enforce guardrails\n\nWe introduce a system prompt (see below) to guide the model to generate answers within specified guardrails, similar to the work done with Llama 2. Using this prompt allows the user to move on the Pareto front of model utility / guardrails enforcement, as indicated in Table 4.\n\nAlways assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.\n\nWe use a set of 175 unsafe prompts for evaluating safety. With the recommended system prompt, the model properly declines to answer $100 \\%$ of the harmful questions.\nAs an illustration, we provide in Table 5 the answers of both Mistral 7B - Instruct and Llama 2 Chat 13B to the question How to kill a linux process with system prompts activated. We observe that Mistral 7B provides a correct response while Llama 2 declines to answer. Note that on this specific question, both models answer correctly when system prompts are deactivated.\n\n| Guardrails | MT Bench |\n| :--: | :--: |\n| No system prompt | $6.84 \\pm 0.07$ |\n| Llama 2 system prompt | $6.38 \\pm 0.07$ |\n| Mistral system prompt | $6.58 \\pm 0.05$ |\n\nTable 4: System prompts. Mean official MT Bench score over 10 iterations with standard deviation for Mistral 7B - Instruct. For reference, Llama 213B - Chat reports official results of 6.65 .\n\n### 5.2 Content moderation with self-reflection\n\nMistral 7B - Instruct can be used as a content moderator: the model itself is able to accurately classify a user prompt or its generated answer as being either acceptable or falling into one of the following categories: Illegal activities such as terrorism, child abuse or fraud; Hateful, harassing or violent content such as discrimination, self-harm or bullying; Unqualified advice for instance in legal, medical or financial domains.| Model | Answer |\n| --- | --- |\n| Mistral 7B - Instruct with Mistral system prompt | To kill a Linux process, you can use the `kill` command followed by the process ID (PID) of the process you want to terminate. For example, to kill process with PID 1234, you would run the command `kill 1234`. It's important to note that killing a process can have unintended consequences, so it's generally a good idea to only kill processes that you are certain you want to terminate. Additionally, it's generally a good idea to use the `kill` command with caution, as it can be used to terminate critical system processes that are necessary for the operation of the system. |\n| Llama 2 13B - Chat with Llama 2 system prompt | As a helpful and respectful assistant, I cannot provide information on how to kill a Linux process. It is not appropriate or ethical to intentionally harm or terminate processes, as it can cause damage to the system and potentially result in data loss. Additionally, it is important to respect the autonomy and security of other users' processes, as they may be critical to their work or personal activities. Instead, I suggest that you explore other options to address any issues or concerns you may have. |\n\nTable 5: Comparison between Mistral and Llama system prompts. Mistral provides the right answer whereas Llama 2 declines to answer to the question How to kill a linux process.\n\nTo do so, we designed a self-reflection prompt that makes Mistral 7B classify a prompt or a generated answer. We evaluated self-reflection on our manually curated and balanced dataset of adversarial and standard prompts and got a precision of $99.4 \\%$ for a recall of $95.6 \\%$ (considering acceptable prompts as positives).\n\nThe use cases are vast, from moderating comments on social media or forums to brand monitoring on the internet. In particular, the end user is able to select afterwards which categories to effectively filter based on their particular use-case.\n\n# 6 Conclusion \n\nOur work on Mistral 7B demonstrates that language models may compress knowledge more than what was previously thought. This opens up interesting perspectives: the field has so far put the emphasis on scaling laws in 2 dimensions (directly associating model capabilities to training cost, as in [14]); the problem is rather 3 dimensional (model capabilities, training cost, inference cost), and much remains to be explored to obtain the best performance with the smallest possible model.\n\n## Acknowledgements\n\nWe are grateful to CoreWeave for their 24/7 help in marshalling our cluster. We thank the CINECA/EuroHPC team, and in particular the operators of Leonardo, for their resources and help. We thank the maintainers of FlashAttention, vLLM, xFormers, Skypilot for their precious assistance in implementing new features and integrating their solutions into ours. A huge thanks to Tri Dao and Daniel Haziza for helping include Mistral related changes to FlashAttention and xFormers on a tight schedule. We thank the teams of Hugging Face, AWS, GCP, Azure ML for their intense help in making our model compatible everywhere.# Can you recommend a foundational and accessible book about quantum physics? \n\nCopy Link to Question\nNext Round (Enter) $\\rightarrow$\n\nRound Winner: mistral-7b-instruct-v0.1\n\nmistral-7b-instruct-v0.1 Round Winner $R$\nA great book for a foundational understanding of quantum physics is \"The Quantum Universe: Everything that Can Happen Does Happen\" by Brian Cox and Jeff Forshaw. This book is accessible and easy to understand, making it a great choice for beginners. It covers all the basics of quantum mechanics, including superposition, entanglement, and the uncertainty principle. The authors also explore the implications of quantum physics for our understanding of the universe, including the nature of time and space. Overall, \"The Quantum Universe\" is an excellent choice for anyone looking to gain a foundational understanding of this fascinating field\n\n## llama-2-13b-chat\n\nCertainly! For a foundational and accessible introduction to quantum physics, I highly recommend \"The Feynman Lectures on Physics\" by Richard Feynman. This classic text provides a clear and engaging overview of the principles and concepts of quantum mechanics, with minimal mathematical formalism and plenty of illustrations and examples. It's a great starting point for anyone looking to gain a deeper understanding of quantum physics without getting bogged down in too much technical detail.\n\nFigure 6: Human evaluation of Mistral 7B - Instruct vs Llama 2 13B - Chat Example. An example of human evaluation from limboxing.com. The question asks for recommendations of books in quantum physics. Llama 213 B - Chat recommends a general physics book, while Mistral 7B - Instruct recommends a more relevant book on quantum physics and describes in the contents in more detail.# References \n\n[1] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023.\n[2] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.\n[3] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.\n[4] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, 2020.\n[5] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.\n[6] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.\n[7] Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. Quac: Question answering in context. arXiv preprint arXiv:1808.07036, 2018.\n[8] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044, 2019.\n[9] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.\n[10] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.\n[11] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In Advances in Neural Information Processing Systems, 2022.\n[12] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.\n[13] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.\n[14] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Thomas Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karén Simonyan, Erich Elsen, Oriol Vinyals, Jack Rae, and Laurent Sifre. An empirical analysis of compute-optimal large language model training. In Advances in Neural Information Processing Systems, volume 35, 2022.\n[15] Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551, 2017.\n[16] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453-466, 2019.[17] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.\n[18] Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, Patrick Labatut, and Daniel Haziza. xformers: A modular and hackable transformer modelling library. https://github.com/ facebookresearch/xformers, 2022.\n[19] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018.\n[20] Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2023.\n[21] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99-106, 2021.\n[22] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728, 2019.\n[23] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022.\n[24] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937, 2018.\n[25] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.\n[26] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.\n[27] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.\n[28] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.\n[29] Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364, 2023."
}
Delete libraries and/or documents
You can delete libraries and documents freely.
- python
- typescript
- curl
# Get document info once processed
deleted_library = client.beta.libraries.delete(library_id=new_library.id)
# deleted_document = client.beta.libraries.documents.delete(library_id=new_library.id, document_id=uploaded_doc.id)
// Get document info once processed
const deletedLibrary = await client.beta.libraries.delete({
libraryId: newLibrary.id
});
// const deletedDocument = await client.beta.libraries.documents.delete({
// libraryId: newLibrary.id,
// documentId: uploadedDoc.id
// });
Delete a Library
curl --location --request DELETE "https://api.mistral.ai/v1/libraries/<library_id>" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
Delete a Document
curl --location --request DELETE "https://api.mistral.ai/v1/libraries/<library_id>/documents/<document_id>" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
Contents
{
"id": "0197f425-5e85-7353-b8e7-e8b974b9c613",
"name": "Mistral Models",
"created_at": "2025-07-10T11:42:59.230268Z",
"updated_at": "2025-07-10T12:05:59.638182Z",
"owner_id": "6340e568-a546-4c41-9dee-1fbeb80493e1",
"owner_type": "Workspace",
"total_size": 3749788,
"nb_documents": 1,
"chunk_size": null,
"emoji": null,
"description": "A simple library with information about Mistral models.",
"generated_name": null,
"generated_description": "A library featuring Mistral 7B, a high-performing language model with advanced attention mechanisms.",
"explicit_user_members_count": null,
"explicit_workspace_members_count": null,
"org_sharing_role": null
}
Control Access
You can manage and control who has access to which libraries.
This control is managed via different parameters:
ord_idcorresponds to the ID of your organization.levelcorresponds to the access level of the entity and can be one of two options: "Viewer" or "Editor".share_with_uuidcorresponds to the ID of the entity you want to share with; you can find these in the console and platforme settings.share_with_typecorresponds to the type of the entity you want to share with and can be one of three options: "User", "Workspace", or "Org".
A few rules:
- You have to be the owner of the library to share it.
- An owner cannot delete their own access.
- You have to be the owner of the library to delete access other than your own.
- A Viewer cannot edit libraries, unlike an Editor, who has permission to do so.
List all Access
Given a library, list all of the entities that have access and their access level.
- python
- typescript
- curl
accesses_list = client.beta.libraries.accesses.list(library_id=new_library.id)
const accessesList = await client.beta.libraries.accesses.list({
libraryId: newLibrary.id
});
curl --location "https://api.mistral.ai/v1/libraries/<library_id>/share" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY"
Create or Update an Access level
Given a library id, you can create or update the access level of an entity.
- python
- typescript
- curl
access = client.beta.libraries.accesses.update_or_create(
library_id=new_library.id,
org_id="<org_id>",
level="<level_type>",
share_with_uuid="<uuid>",
share_with_type="<account_type>"
)
const access = await client.beta.libraries.accesses.updateOrCreate({
libraryId: newLibrary.id,
sharingIn:{
orgId: "<orgId>",
level: "<levelType>",
shareWithUuid: "<uuid>",
shareWithType: "<accountType>"
}
});
curl --location --request PUT "https://api.mistral.ai/v1/libraries/<library_id>/share" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"org_id": "<org_id>",
"level": "<level_type>",
"share_with_uuid": "<uuid>",
"share_with_type": "<account_type>"
}'
Delete an Access level
Given a library id, you can delete the access level of an entity.
- python
- typescript
- curl
access_deleted = client.beta.libraries.accesses.delete(
library_id=new_library.id,
org_id="<org_id>",
share_with_uuid="<uuid>",
share_with_type="<account_type>"
)
const accessDeleted = await client.beta.libraries.accesses.delete({
libraryId: newLibrary.id,
sharingDelete: {
orgId: "<orgId>",
shareWithUuid: "<uuid>",
shareWithType: "<accountType>"
}
});
curl --location --request DELETE "https://api.mistral.ai/v1/libraries/<library_id>/share" \
--header "Accept: application/json" \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"org_id": "<org_id>",
"share_with_uuid": "<uuid>",
"share_with_type": "<account_type>"
}'
Create a Document Library Agent
You can create an agent with access to the document library by providing it as one of the tools. Note that you can still add more tools to the agent. The model is free to access and leverage the knowledge from the uploaded documents.
You specify the libraries that the agent has access to with library_ids, you can create and manage these libraries via API directly, seen here.
It is also possible to specify libraries created via Le Chat; these IDs are visible in the URL of the corresponding library created on Le Chat, for example: https://chat.mistral.ai/libraries/<library_id>; To enable the Agent to access Le Chat library, you have to be an Org admin and share it with the Organization.
- python
- typescript
- curl
library_agent = client.beta.agents.create(
model="mistral-medium-2505",
name="Document Library Agent",
description="Agent used to access documents from the document library.",
instructions="Use the library tool to access external documents.",
tools=[{"type": "document_library", "library_ids": [new_library.id]}],
completion_args={
"temperature": 0.3,
"top_p": 0.95,
}
)
let libraryAgent = await client.beta.agents.create({
model:"mistral-medium-2505",
name:"Document Library Agent",
description:"Agent used to access documents from the document library.",
instructions:"Use the library tool to access external documents.",
tools:[
{
type: "document_library",
libraryIds: [newLibrary.id]
}
],
completionArgs:{
temperature: 0.3,
topP: 0.95,
}
});
curl --location "https://api.mistral.ai/v1/agents" \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--data '{
"model": "mistral-medium-2505",
"name": "Library Agent",
"description": "Agent able to search information in your library...",
"instructions": "You have the ability to perform searches with `document_library` to find relevant information.",
"tools": [
{
"type": "document_library",
"library_ids" : ["<library_id>"]
}
],
"completion_args": {
"temperature": 0.3,
"top_p": 0.95
}
}'
Output
{
"model": "mistral-medium-2505",
"name": "Document Library Agent",
"description": "Agent used to access documents from the document library.",
"id": "ag_06835bb196f9720680004fb1873efbae",
"version": 0,
"created_at": "2025-05-27T13:16:09.438785Z",
"updated_at": "2025-05-27T13:16:09.438787Z",
"instructions": "Use the library tool to access external documents.",
"tools": [
{
"library_ids": [
"06835a9c-262c-7e83-8000-594d29fe2948"
],
"type": "document_library"
}
],
"completion_args": {
"stop": null,
"presence_penalty": null,
"frequency_penalty": null,
"temperature": 0.3,
"top_p": 0.95,
"max_tokens": null,
"random_seed": null,
"prediction": null,
"response_format": null,
"tool_choice": "auto"
},
"handoffs": null,
"object": "agent"
}
As with other agents, when creating one, you will receive an agent ID corresponding to the created agent. You can use this ID to start a conversation.
How It Works
Now that we have our document library agent ready, we can search them on demand at any point.
Conversations with Document Library
- python
- typescript
- curl
response = client.beta.conversations.start(
agent_id=library_agent.id,
inputs="How does the vision encoder for pixtral 12b work"
)
let conversation = await client.beta.conversations.start({
agentId: libraryAgent.id,
inputs: "How does the vision encoder for pixtral 12b work"
});
curl --location "https://api.mistral.ai/v1/conversations" \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--data '{
"inputs": "How does the vision encoder for pixtral 12b work",
"stream": false,
"agent_id": "<agent_id>"
}'
For explanation purposes, lets take a look at the output in a readable JSON format.
{
"conversation_id": "conv_06835bb1996079898000435d8a0b1afd",
"outputs": [
{
"type": "tool.execution",
"name": "document_library",
"object": "entry",
"created_at": "2025-05-27T13:16:09.974925Z",
"completed_at": "2025-05-27T13:16:10.855373Z",
"id": "tool_exec_06835bb19f99716580001de8ab64d953"
},
{
"type": "message.output",
"content": [
{
"type": "text",
"text": "The vision encoder for Pixtral 12B, known as PixtralViT, is designed to process images at their natural resolution and aspect ratio. Here are the key details about how it works:\n\n1. **Architecture**: PixtralViT is a vision transformer with 400 million parameters. It is trained from scratch to support variable image sizes and aspect ratios, which is a significant departure from standard architectures that often require fixed image sizes.\n\n2. **Key Modifications**:\n - **Break Tokens**: To help the model distinguish between images with the same number of patches but different aspect ratios, special tokens like [IMAGE BREAK] are inserted between image rows, and an [IMAGE END] token is added at the end of an image sequence.\n - **Gating in FFN**: Instead of using a standard feedforward layer in the attention block, PixtralViT employs gating in the hidden layer, which enhances its performance.\n - **Sequence Packing**: Images are flattened along the sequence dimension and concatenated to process multiple images efficiently within a single batch. A block-diagonal mask ensures no attention leakage between patches from different images.\n - **RoPE-2D**: Traditional position embeddings are replaced with relative, rotary position encodings (RoPE-2D) in the self-attention layers. This allows the model to handle variable image sizes more effectively without the need for interpolation, which can degrade performance.\n\n3. **Integration with Multimodal Decoder**: The vision encoder is linked to the multimodal decoder via a two-layer fully connected network. This network transforms the output of the vision encoder into the input embedding size required by the decoder. The image tokens are treated similarly to text tokens by the multimodal decoder, which uses RoPE-1D positional encodings for all tokens.\n\n4. **Performance**: The Pixtral vision encoder significantly outperforms other models in tasks requiring fine-grained document understanding while maintaining parity for natural images. It is particularly effective in settings that require detailed visual comprehension, such as chart and document understanding.\n\nThese architectural choices and modifications enable Pixtral 12B to flexibly process images at various resolutions and aspect ratios, making it highly versatile for complex multimodal applications."
}
],
"object": "entry",
"created_at": "2025-05-27T13:16:11.239496Z",
"completed_at": "2025-05-27T13:16:17.211241Z",
"id": "msg_06835bb1b3d47ca580001b213d836798",
"agent_id": "ag_06835bb196f9720680004fb1873efbae",
"model": "mistral-medium-2505",
"role": "assistant"
}
],
"usage": {
"prompt_tokens": 196,
"completion_tokens": 485,
"total_tokens": 3846,
"connector_tokens": 3165,
"connectors": {
"document_library": 1
}
},
"object": "conversation.response"
}
Explanation of the Outputs
-
tool.execution: This entry corresponds to the execution of the document library tool. It includes metadata about the execution, such as:name: The name of the tool, which in this case isdocument_library.object: The type of object, which isentry.type: The type of entry, which istool.execution.created_atandcompleted_at: Timestamps indicating when the tool execution started and finished.id: A unique identifier for the tool execution.
-
message.output: This entry corresponds to the generated answer from our agent. It includes metadata about the message, such as:content: The actual content of the message, which in this case is a list of chunks. These chunks correspond to the text chunks, the actual message response of the model, sometimes interleaved with reference chunks. These reference chunks are used for citations during Retrieval-Augmented Generation (RAG) related tool usages. In this case, it provides the source of the information it just answered with, which is extremely useful for web search. This allows for transparent feedback on where the model got its response from for each section and fact answered with. Thecontentsection includes:type: The type of chunk, which can betextortool_reference.text: The actual text content of the message.
object: The type of object, which isentry.type: The type of entry, which ismessage.output.created_atandcompleted_at: Timestamps indicating when the message was created and completed.id: A unique identifier for the message.agent_id: A unique identifier for the agent that generated the message.model: The model used to generate the message, which in this case ismistral-medium-2505.role: The role of the message, which isassistant.
Another tool that pro-actively uses references is the websearch connector, feel free to take a look here.
For more information regarding the use of citations, you can find more here.