Tokenization
Tokenization is a fundamental step in LLMs. It is the process of breaking down text into smaller subword units, known as tokens. We recently open-sourced our tokenizer at Mistral AI. This guide will walk you through the fundamentals of tokenization, details about our open-source tokenizers, and how to use our tokenizers in Python.
What is tokenization?
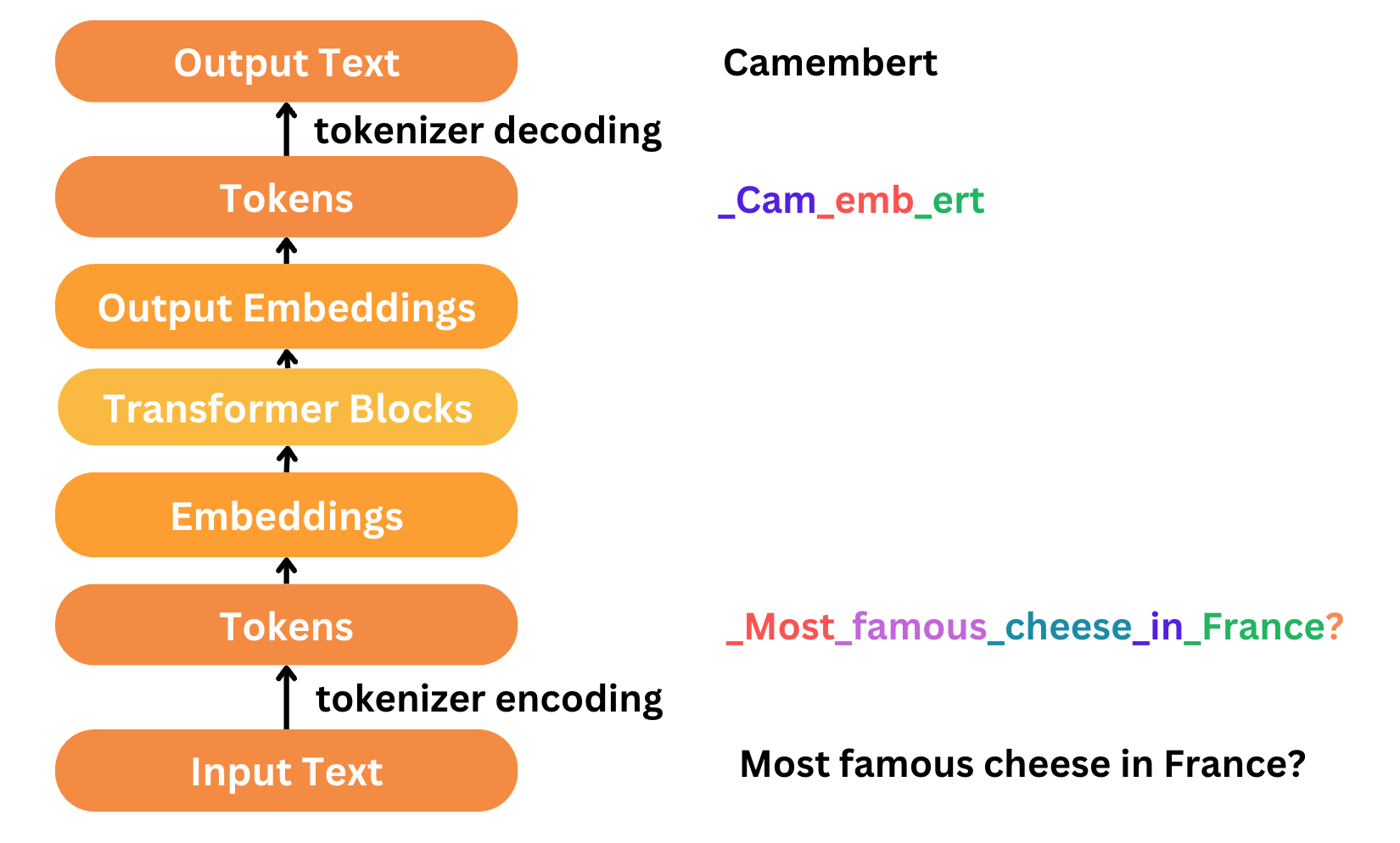
Tokenization is the first step and the last step of text processing and modeling. Texts need to be represented as numbers in our models so that our model can understand. Tokenization breaks down text into tokens, and each token is assigned a numerical representation, or index, which can be used to feed into a model. In a typical LLM workflow:
- We first encode the input text into tokens using a tokenizer. Each unique token is assigned a specific index number in the tokenizer’s vocabulary.
- Once the text is tokenized, these tokens are passed through the model, which typically includes an embedding layer and transformer blocks. The embedding layer converts the tokens into dense vectors that capture semantic meanings. Check out our embedding guide for details. The transformer blocks then process these embedding vectors to understand the context and generate results.
- The last step is decoding, which detokenize output tokens back to human-readable text. This is done by mapping the tokens back to their corresponding words using the tokenizer’s vocabulary.
Most people only tokenize text. Our first release contains tokenization. Our tokenizers go beyond the usual text <-> tokens, adding parsing of tools and structured conversation. We also release the validation and normalization code that is used in our API. Specifically, we use control tokens, which are special tokens to indicate different types of elements. These tokens are not treated as strings and are added directly to the code. Note that we are still iterating on the tokenizer. Things may change and this is the current state of things.
We have released three versions of our tokenizers powering different sets of models.
- v1:
open-mistral-7b,open-mixtral-8x7b,mistral-embed - v2:
mistral-small-latest,mistral-large-latest - v3:
open-mixtral-8x22b
Below is an example of 3 turns of conversations using v3, showcasing how the control tokens are structured around the available tools, user message, tool calls and tool results. This guide will focus on our latest v3 tokenizer.

Building the vocabulary
There are several tokenization methods used in Natural Language Processing (NLP) to convert raw text into tokens such as word-level tokenization, character-level tokenization, and subword-level tokenization including the Byte-Pair Encoding (BPE). Our tokenizers use the Byte-Pair Encoding (BPE) with SentencePiece, which is an open-source tokenization library to build our tokenization vocabulary.
In BPE, the tokenization process starts by treating each byte in a text as a separate token. Then, it iteratively adds new tokens to the vocabulary for the most frequent pair of tokens currently appearing in the corpus. For example, if the most frequent pair of tokens is "th" + "e", then a new token "the" will be created and occurrences of "th"+"e" will be replaced with the new token "the". This process continues until no more replacements can be made.
Our tokenization vocabulary
Our tokenization vocabulary is released in the https://github.com/mistralai/mistral-common/tree/main/tests/data folder. Let’s take a look at the vocabulary of our v3 tokenizer.
Vocabulary size
Our vocabulary consists of 32k vocab + 768 control tokens. The 32k vocab includes 256 bytes and 31,744 characters and merged characters.
Control tokens
Our vocabulary starts with 10 control tokens, which are special tokens we use in the encoding process to represent specific instructions or indicators:
<unk>
<s>
</s>
[INST]
[/INST]
[TOOL_CALLS]
[AVAILABLE_TOOLS]
[/AVAILABLE_TOOLS]
[TOOL_RESULTS]
[/TOOL_RESULTS]
The tokenizer does not encode control tokens, which help prevent a situation known as prompt injection. For example, the control token “[INST]” is used to denote user message:
- Without the control tokens, the tokenizer treats “[INST]” as a regular string and encodes the entire sequence “[INST] I love Paris [/INST]”. This could potentially allow users to include "[INST]" and "[/INST]" tags within their message, causing confusion for the model as it might interpret part of the user's message as an assistant's message.
- With the control tokens, the tokenizer instead concatenates the control tokens with the encoded message: [INST] + encode(“I love Paris”) + [/INST]. This ensures that only the user's message gets encoded, and the encoded messages are guaranteed to have the correct [INST] and [/INST] tags.
You may have noticed that we have 768 slots for control tokens. The remaining 761 slots for control tokens are actually empty for us to add more control tokens in the future and also ensure our vocabulary size is 32,768 (2^15). Computers like powers of 2s!
Bytes
After the control token slots, we have 256 bytes in the vocabulary. A byte is a unit of digital information that consists of 8 bits. Each bit can represent one of two values, either 0 or 1. A byte can therefore represent 256 different values.
<0x00>
<0x01>
...
Any character, regardless of the language or symbol, can be represented by a sequence of one or more bytes. When a word is not present in the vocabulary, it can still be represented by the bytes that correspond to its individual characters. This is important for handling unknown words and characters.
Characters and merged characters
And finally, we have the characters and merged characters in the vocabulary. The order of the tokens are determined by the frequency of these tokens in the data that was used to train the model, with the most frequent ones in the beginning of the vocabulary. For example, two spaces “▁”, four spaces “▁▁▁▁”, “_t”, “in”, and “er” were found to be the most common tokens we trained on. As we move further down the vocabulary list, the tokens become less frequent. Towards the end of the vocabulary file, you might find less common characters such as Chinese and Korean characters. These characters are less frequent because they were encountered less often in the training data, not because they are less used in general.
▁▁
▁▁▁▁
▁t
in
er
...
벨
ゼ
梦
Run our tokenizer in Python
To get started, let’s first install our tokenizer via pip install mistral-common.
Once the tokenizer is installed, in a Python environment, we can import the needed modules from mistral_common.
from mistral_common.protocol.instruct.messages import (
AssistantMessage,
UserMessage,
ToolMessage
)
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.tool_calls import Function, Tool, ToolCall, FunctionCall
from mistral_common.tokens.instruct.normalize import ChatCompletionRequest
We load our tokenizer with MistralTokenizer and specify which version of tokenizer we’d like to load.
tokenizer_v3 = MistralTokenizer.v3()
Let’s tokenize a series of conversation with different types of messages
tokenized = tokenizer_v3.encode_chat_completion(
ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris"),
AssistantMessage(
content=None,
tool_calls=[
ToolCall(
id="VvvODy9mT",
function=FunctionCall(
name="get_current_weather",
arguments='{"location": "Paris, France", "format": "celsius"}',
),
)
],
),
ToolMessage(
tool_call_id="VvvODy9mT", name="get_current_weather", content="22"
),
AssistantMessage(
content="The current temperature in Paris, France is 22 degrees Celsius.",
),
UserMessage(content="What's the weather like today in San Francisco"),
AssistantMessage(
content=None,
tool_calls=[
ToolCall(
id="fAnpW3TEV",
function=FunctionCall(
name="get_current_weather",
arguments='{"location": "San Francisco", "format": "celsius"}',
),
)
],
),
ToolMessage(
tool_call_id="fAnpW3TEV", name="get_current_weather", content="20"
),
],
model="test",
)
)
tokens, text = tokenized.tokens, tokenized.text
Here is the output of “text”, which is a debug representation for you to inspect.
'<s>[INST] What\'s the weather like today in Paris[/INST][TOOL_CALLS] [{"name": "get_current_weather", "arguments": {"location": "Paris, France", "format": "celsius"}, "id": "VvvODy9mT"}]</s>[TOOL_RESULTS] {"call_id": "VvvODy9mT", "content": 22}[/TOOL_RESULTS] The current temperature in Paris, France is 22 degrees Celsius.</s>[AVAILABLE_TOOLS] [{"type": "function", "function": {"name": "get_current_weather", "description": "Get the current weather", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"}, "format": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The temperature unit to use. Infer this from the users location."}}, "required": ["location", "format"]}}}][/AVAILABLE_TOOLS][INST] What\'s the weather like today in San Francisco[/INST][TOOL_CALLS] [{"name": "get_current_weather", "arguments": {"location": "San Francisco", "format": "celsius"}, "id": "fAnpW3TEV"}]</s>[TOOL_RESULTS] {"call_id": "fAnpW3TEV", "content": 20}[/TOOL_RESULTS]'
To count the number of tokens, run len(tokens) and we get 302 tokens.
Use cases
NLP tasks
As we mentioned earlier, tokenization is a crucial first step in natural language processing (NLP) tasks. Once we have tokenized our text, we can use those tokens to create text embeddings, which are dense vector representations of the text. These embeddings can then be used for a variety of NLP tasks, such as text classification, sentiment analysis, and machine translation.
Mistral's embedding API simplifies this process by combining the tokenization and embedding steps into one. With this API, we can easily create text embeddings for a given text, without having to separately tokenize the text and create embeddings from the tokens.
If you're interested in learning more about how to use Mistral's embedding API, be sure to check out our embedding guide, which provides detailed instructions and examples.
Tokens count
Mistral AI's LLM API endpoints charge based on the number of tokens in the input text.
To help you estimate your costs, our tokenization API makes it easy to count the number of tokens in your text. Simply run len(tokens) as shown in the example above to get the total number of tokens in the text, which you can then use to estimate your cost based on our pricing information.