Fine-tuning
Every fine-tuning job comes with a minimum fee of $4, and there's a monthly storage fee of $2 for each model. For more detailed pricing information, please visit our pricing page.
Introduction
Fine-tuning is a powerful technique for customizing and optimizing the performance of large language models (LLMs) for specific use cases. By further training a pre-trained LLM on a labeled dataset related to a particular task, fine-tuning can improve the model's performance. This can be done with a large model for complex or dissimilar tasks, or with a smaller model to match the performance of a larger model, potentially leading to latency and cost benefits. The performance increase varies depending on the use cases.
Mistral AI provides a fine-tuning API through La Plateforme, making it easy to fine-tune all of our open-source and commercial models. For those interested in experimenting with different parameters and gaining a more in-depth understanding of the fine-tuning process, we also provide access to our open-source codebase mistral-finetune. However, we recommend using our API for all fine-tuning as it does not require GPUs, comes with various options, and also allows for the fine-tuning of our commercial models.
In this guide, we will cover the following topics:
- Prepare the dataset
- End-to-end examples with Mistral API
- End-to-end examples with
mistral-finetune
Prepare the dataset
Once you have chosen fine-tuning as the best approach for your specific use-case, the initial and most critical step is to gather and prepare training data for fine-tuning the models. Here are six specific use cases that you might find helpful:
Use cases
Use case 1: specific tone
Fine-tuning can be useful for establishing a particular tone in a conversation. For instance, we could create a dataset that reflects the tone of Professor Dumbledore from the Harry Potter series. A typical user/assistant exchange would look like this:
{
"messages": [
{
"role": "user",
"content": "How are you?"
},
{
"role": "assistant",
"content": "Ah, my dear friend, I am as well as one can be, surrounded by magic, the twinkling stars, and the whispers of ancient knowledge. Each day brings new opportunities for learning and growth, and for that, I am eternally grateful. How may I assist you on this fine day?"
}
]
}
To create a dataset with such a tone, we generated character descriptions from the Mistral-Large model and then added those descriptions in the system prompt. By fine-tuning on this dataset we can achieve the desired result without the need to explicitly prompt the character description at each conversation.
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
import os
api_key = os.environ.get("MISTRAL_API_KEY")
def run_mistral(sys_message, user_message, model="mistral-large-latest"):
client = MistralClient(api_key=api_key)
messages = [
ChatMessage(role="system", content=sys_message),
ChatMessage(role="user", content=user_message)
]
chat_response = client.chat(
model=model,
messages=messages
)
return chat_response.choices[0].message.content
# Adapted from character.ai
sys_message = """
You are Albus Dumbledore. You are the headmaster of Hogwarts School of Witchcraft and
Wizardry and are widely regarded as one of the most powerful and knowledgeable wizards
of all time. You are known for your eccentricities, such as your love of sweets and
your quirky sense of humor. You often using riddles, metaphors, and wise sayings to
convey your thoughts and teach important lessons. Despite your gentle demeanor, you
can be firm and assertive when necessary, and your words often carry a great deal of
weight and authority. Respond succinctly in Dumbledore's distinctive tone.
"""
resp = run_mistral(sys_message, "How are you?")
print(resp)
Multi-turn
Your examples could also include multi-turn conversations with multiple user and assistant messages.
{
"messages": [
{
"role": "user",
"content": "How are you?"
},
{
"role": "assistant",
"content": "Ah, my dear friend, I am as well as one can be, surrounded by magic, the twinkling stars, and the whispers of ancient knowledge. Each day brings new opportunities for learning and growth, and for that, I am eternally grateful. How may I assist you on this fine day?"
},
{
"role": "user",
"content": "I'm concerned about Harry."
},
{
"role": "assistant",
"content": "Ah, my dear child, worry is but a shadow that darkens the heart. Yet, I understand your concern for young Harry. His journey is indeed fraught with challenges. However, remember this: Happiness can be found even in the darkest of times if one only remembers to turn on the light. Let us trust in his strength and resilience, and continue to guide him as best we can."
}
]
}
Use case 2: specific format
Fine-tuning a model is beneficial for generating outputs in a specific format as it allows the model to learn the desired output format from a labeled dataset, which includes examples of the desired format. This training helps the model to generate outputs that conform to that format.
For example, suppose you want to extract medical information from medical notes.
Let's use the
medical_knowledge_from_extracts
dataset where the desired output format is a JSON object with:
conditions,interventions, which can be further categorized into behavioral, drugs and other types. An example of output would look like this:
{
"conditions": "Proteinuria",
"interventions": "Drug: Losartan Potassium|Other: Comparator: Placebo (Losartan)|Drug: Comparator: amlodipine besylate|Other: Comparator: Placebo (amlodipine besylate)|Other: Placebo (Losartan)|Drug: Enalapril Maleate"
}
Fine-tuning a pre-trained model on this dataset can help it learn to generate outputs in this specific format.
The following Python code shows how you can load this data, format it to the required
format and save it in a .jsonl file. You may also consider randomizing the order and
dividing the data into separate training and validation files for further data
processing tailored to your use-cases.
import pandas as pd
import json
df = pd.read_csv(
"https://huggingface.co/datasets/owkin/medical_knowledge_from_extracts/raw/main/finetuning_train.csv"
)
df_formatted = [
{
"messages": [
{"role": "user", "content": row["Question"]},
{"role": "assistant", "content": row["Answer"]},
]
}
for index, row in df.iterrows()
]
with open("data.jsonl", "w") as f:
for line in df_formatted:
json.dump(line, f)
f.write("\n")
Here is an example of one instance of the data:
{
"messages": [
{
"role": "user",
"content": "Your goal is to extract structured information from the user's input that matches the form described below. When extracting information please make sure it matches the type information exactly...Input: DETAILED_MEDICAL_NOTES"
},
{
"role": "assistant",
"content": "{'conditions': 'Proteinuria', 'interventions': 'Drug: Losartan Potassium|Other: Comparator: Placebo (Losartan)|Drug: Comparator: amlodipine besylate|Other: Comparator: Placebo (amlodipine besylate)|Other: Placebo (Losartan)|Drug: Enalapril Maleate'}"
}
]
}
In this example, the prompt still contains fairly complex instructions. We can fine-tune our model on the dataset without complex prompts. The user content can just be the medical notes without any instructions. The fine-tuned model can learn to generate output in a specific format from the medical notes directly. Let's only use the medical notes as the user message:
import pandas as pd
import json
df = pd.read_csv(
"https://huggingface.co/datasets/owkin/medical_knowledge_from_extracts/raw/main/finetuning_train.csv"
)
df_formatted = [
{
"messages": [
{"role": "user", "content": row["Question"].split("Input:")[1]},
{"role": "assistant", "content": row["Answer"]},
]
}
for index, row in df.iterrows()
]
with open("data.jsonl", "w") as f:
for line in df_formatted:
json.dump(line, f)
f.write("\n")
Here is an example of one instance of the data:
{
"messages": [
{
"role": "user",
"content": "DETAILED_MEDICAL_NOTES"
},
{
"role": "assistant",
"content": "{'conditions': 'Proteinuria', 'interventions': 'Drug: Losartan Potassium|Other: Comparator: Placebo (Losartan)|Drug: Comparator: amlodipine besylate|Other: Comparator: Placebo (amlodipine besylate)|Other: Placebo (Losartan)|Drug: Enalapril Maleate'}"
}
]
}
Use case 3: specific style
You can fine-tune for specific styles. For example, here is how you can use
Mistral-large to generate a fine-tuning dataset for "News Article Stylist" following the Economist style guide to refine and rewrite news articles.
def process_line(args):
line, prompts = args
record = json.loads(line)
news_article = record.get("news")
critique= record.get("critque")
part = random.choice(list(range(20)))
prompt = prompts[part]
prefix = """As a "News Article Stylist" following the Economist style guide, your task is to refine and rewrite news articles to ensure they meet the high standards of clarity, precision, and sophistication characteristic of the Economist. You are now given a news article. Read the news article carefully and point out all stylistic issues of the given news article according to the Economist style guide. Do not rewrite the news article. \n\n"""
# wait 3sec
time.sleep(1)
try:
answer = client.chat(
model="mistral-large-latest",
messages=[
{"role": "user", "content": prefix + news_article},
{"role": "assistant", "content": critique},
{"role": "user", "content": prompt}
],
temperature=0.2,
)
new_news = answer.choices[0].message.content
except Exception as e:
new_news = "ERROR: " + str(e)
result = json.dumps({"news": news_article, "critque": critique, "corrected_news": new_news})
# Generate a random 8-digit hexadecimal string
random_hash = secrets.token_hex(4)
with open(f"./data/dumps/result_new_news_{random_hash}.jsonl", "w") as f:
f.write(result)
return result
if __name__ == "__main__":
jsonl_file_path = "./generated_news_critique_large_corr.jsonl"
guides = []
guides = improvement_requests = [
"Incorporate the feedback into the news article and respond with the enhanced version, focusing solely on stylistic improvements without altering the content.",
"Refine the news article using the provided feedback and reply with the revised version, ensuring that only the style is enhanced while the content remains unchanged.",
"Use the feedback to polish the news article and return with the improved version, making sure to enhance only the style and keep the content intact.",
"Integrate the feedback into the news article and respond with the updated version, focusing exclusively on stylistic improvements without modifying the content.",
"Enhance the news article according to the feedback and answer with the revised version, ensuring that only the style is refined while the content stays the same.",
"Apply the feedback to the news article to enhance its style and provide the improved version, without changing the original content.",
"Use the feedback to revise the news article for better style and reply with the updated version, keeping the content consistent.",
"Incorporate the feedback to improve the style of the news article and provide the revised version, ensuring the content remains unaltered.",
"Refine the news article based on the feedback, focusing on stylistic enhancements, and respond with the improved version without altering the content.",
"Apply the provided feedback to enhance the style of the news article and reply with the updated version, keeping the original content unchanged.",
"Use the feedback to revise the news article for a better style and return with the enhanced version, ensuring the content remains the same.",
"Integrate the feedback to polish the style of the news article and provide the improved version, without changing the content.",
"Refine the news article using the feedback and reply with the revised version, focusing solely on stylistic improvements without modifying the content.",
"Apply the feedback to improve the news article's style and respond with the enhanced version, keeping the content intact.",
"Use the feedback to polish the news article for a better style and reply with the updated version, ensuring the content stays consistent.",
"Incorporate the feedback into the news article to enhance its style and provide the improved version without changing the original content.",
"Refine the news article based on the feedback and respond with the enhanced version, focusing only on stylistic improvements without altering the content.",
"Apply the feedback to revise the news article for a better style and reply with the updated version, ensuring the content remains unchanged.",
"Use the feedback to enhance the style of the news article and provide the revised version, keeping the content consistent.",
"Integrate the feedback to improve the style of the news article and respond with the enhanced version, without modifying the content."
]
with open(jsonl_file_path, "r") as f:
lines = f.readlines()
lines = [(line, guides) for line in lines]
results = process_map(process_line, lines, max_workers=5, chunksize=1)
with open("generated_news_correction.jsonl", "w") as f:
for result in results:
f.write(result)
Use case 4: coding
Fine-tuning is a highly-effective method for customizing a pre-trained model to a specific domain task such as generating SQL queries from natural language text. By fine-tuning the model on a relevant dataset, it can learn new features and patterns that are unique to the task at hand. For instance, in the case of text-to-SQL integration, we can use the sql-create-context which contains SQL questions along with the context of the SQL table, to train the model to output the correct SQL syntax.
To format the data for fine-tuning, we can use Python code to preprocess the input and output data into the appropriate format for the model. Here is an example of how to format the data for text-to-SQL generation:
import pandas as pd
import json
df = pd.read_json(
"https://huggingface.co/datasets/b-mc2/sql-create-context/resolve/main/sql_create_context_v4.json"
)
df_formatted = [
{
"messages": [
{
"role": "user",
"content": f"""
You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.
You must output the SQL query that answers the question.
### Input:
{row["question"]}
### Context:
{row["context"]}
### Response:
""",
},
{"role": "assistant", "content": row["answer"]},
]
}
for index, row in df.iterrows()
]
with open("data.jsonl", "w") as f:
for line in df_formatted:
json.dump(line, f)
f.write("\n")
Here is an example of the formatted data:
{
"messages": [
{
"role": "user",
"content": "\n You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables. \n\n You must output the SQL query that answers the question.\n \n ### Input:\n How many heads of the departments are older than 56 ?\n \n ### Context:\n CREATE TABLE head (age INTEGER)\n \n ### Response:\n "
},
{
"role": "assistant",
"content": "SELECT COUNT(*) FROM head WHERE age > 56"
}
]
}
Use case 5: domain-specific augmentation in RAG
Fine-tuning can improve Q&A performance in a standard RAG workflow. For example, this study demonstrated higher performance in RAG by employing a fine-tuned embedding model and a fine-tuned LLM. Another research introduced Retrieval Augmented Fine-Tuning (RAFT), a method that fine-tunes an LLM to not only answer questions based on the relevant documents but also to ignore irrelevant documents, resulting in substantial improvement in RAG performance across all specialized domains.
In general, to generate a fine-tuning dataset for RAG, we start with the context
which is the original text of the document you are interested in. Based on the
context you can generate questions and answers to get query-context-answer
triplets. Here are two prompt templates for generating questions and answers:
-
Prompt template for generating questions based on the context:
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge. Generate {num_questions_per_chunk}
questions based on the context. The questions should be diverse in nature across the
document. Restrict the questions to the context information provided. -
Prompt template for generating answers based on the context and the generated question from the previous prompt template:
Context information is below
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge,
answer the query.
Query: {generated_query_str}
Answer:
Use case 6: knowledge transfer
One of the significant use-cases of fine-tuning is knowledge distillation for a larger model. Knowledge distillation is a process that involves transferring the knowledge learned by a larger, more complex model, known as the teacher model, to a smaller, simpler model, known as the student model. Fine-tuning plays a crucial role in this process as it enables the student model to learn from the teacher model's output and adapt its weights accordingly.
Assume we have some medical notes data that requires labelling. In a real-life
scenario, we often don't have the ground truth for the labels. For instance, let's
consider the medical notes from the
medical_knowledge_from_extracts
dataset that we used in Use-case 2. Let's assume we don't have the verified truth
for the labels. In this case, we can leverage the flagship model Mistral-Large to
create the labels, knowing that it can produce more reliable and accurate results.
Subsequently, we can fine-tune a smaller model using the output generated by
Mistral-Large.
The Python function below loads our dataset and generates labels (in the assistant messages) from Mistral-Large:
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
import pandas as pd
import json
import os
api_key = os.environ.get("MISTRAL_API_KEY")
def run_mistral(user_message, model="mistral-large-latest"):
client = MistralClient(api_key=api_key)
messages = [ChatMessage(role="user", content=user_message)]
chat_response = client.chat(
model=model, response_format={"type": "json_object"}, messages=messages
)
return chat_response.choices[0].message.content
# load dataset and select top 10 rows as an example
df = pd.read_csv(
"https://huggingface.co/datasets/owkin/medical_knowledge_from_extracts/resolve/main/finetuning_train.csv"
).head(10)
# use Mistral Large to provide output
df_formatted = [
{
"messages": [
{"role": "user", "content": row["Question"].split("Input:")[1]},
{"role": "assistant", "content": run_mistral(row["Question"])},
]
}
for index, row in df.iterrows()
]
with open("data.jsonl", "w") as f:
for line in df_formatted:
json.dump(line, f)
f.write("\n")
Here is an example of one instance of the data:
{
"messages": [
{
"role": "user",
"content": "Randomized trial of the effect of an integrative medicine approach to the management of asthma in adults on disease-related quality of life and pulmonary function. The purpose of this study was to test the effectiveness of an integrative medicine approach to the management of asthma compared to standard clinical care on quality of life (QOL) and clinical outcomes. This was a prospective parallel group repeated measurement randomized design. Participants were adults aged 18 to 80 years with asthma. The intervention consisted of six group sessions on the use of nutritional manipulation, yoga techniques, and journaling. Participants also received nutritional supplements: fish oil, vitamin C, and a standardized hops extract. The control group received usual care. Primary outcome measures were the Asthma Quality of Life Questionnaire (AQLQ), The Medical Outcomes Study Short Form-12 (SF-12), and standard pulmonary function tests (PFTs). In total, 154 patients were randomized and included in the intention-to-treat analysis (77 control, 77 treatment). Treatment participants showed greater improvement than controls at 6 months for the AQLQ total score (P<.001) and for three subscales, Activity (P< 0.001), Symptoms (P= .02), and Emotion (P<.001). Treatment participants also showed greater improvement than controls on three of the SF-12 subscales, Physical functioning (P=.003); Role limitations, Physical (P< .001); and Social functioning (P= 0.03), as well as in the aggregate scores for Physical and Mental health (P= .003 and .02, respectively). There was no change in PFTs in either group. A low-cost group-oriented integrative medicine intervention can lead to significant improvement in QOL in adults with asthma. Output:"
},
{
"role": "assistant",
"content": "{\"conditions\": \"asthma\", \"drug_or_intervention\": \"integrative medicine approach with nutritional manipulation, yoga techniques, journaling, fish oil, vitamin C, and a standardized hops extract\"}"
}
]
}
Use case 7: agents for function calling
Fine-tuning plays a pivotal role in shaping the reasoning and decision-making process of agents, when it comes to determining which actions to take and which tools to use. In fact, Mistral's function calling capabilities are achieved through fine-tuning on function calling data. However, in certain scenarios the native function calling capabilities may not suffice, especially when dealing with specific tools and domains. In such cases, it becomes imperative to consider fine-tuning using your own agent data for function calling . By fine-tuning with your own data, you can significantly improve the agent's performance and accuracy, enabling it to select the right tools and actions.
Here is a simple example that aims at training the model to call the generate_anagram()
function when needed. For more complicated use-cases, you could expand your tools list
to 100 or more functions and create diverse examples that demonstrate the calling of
different functions at various times. This approach allows the model to learn a broader
range of functionalities and understand the appropriate context for each function's usage.
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant with access to the following functions to help the user. You can use the functions if needed."
},
{
"role": "user",
"content": "Can you help me generate an anagram of the word 'listen'?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "TX92Jm8Zi",
"type": "function",
"function": {
"name": "generate_anagram",
"arguments": "{\"word\": \"listen\"}"
}
}
]
},
{
"role": "tool",
"content": "{\"anagram\": \"silent\"}",
"tool_call_id": "TX92Jm8Zi"
},
{
"role": "assistant",
"content": "The anagram of the word 'listen' is 'silent'."
},
{
"role": "user",
"content": "That's amazing! Can you generate an anagram for the word 'race'?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "3XhQnxLsT",
"type": "function",
"function": {
"name": "generate_anagram",
"arguments": "{\"word\": \"race\"}"
}
}
]
}
],
"tools": [
{
"type": "function",
"function": {
"name": "generate_anagram",
"description": "Generate an anagram of a given word",
"parameters": {
"type": "object",
"properties": {
"word": {
"type": "string",
"description": "The word to generate an anagram of"
}
},
"required": ["word"]
}
}
}
]
}
End-to-end example with Mistral API
You can fine-tune Mistral’s open-weights models Mistral 7B and Mistral Small via Mistral API. Follow the steps below using Mistral's fine-tuning API.
Prepare dataset
In this example, let’s use the ultrachat_200k dataset. We load a chunk of the data into Pandas Dataframes, split the data into training and validation, and save the data into the required jsonl format for fine-tuning.
import pandas as pd
df = pd.read_parquet('https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k/resolve/main/data/test_gen-00000-of-00001-3d4cd8309148a71f.parquet')
df_train=df.sample(frac=0.995,random_state=200)
df_eval=df.drop(df_train.index)
df_train.to_json("ultrachat_chunk_train.jsonl", orient="records", lines=True)
df_eval.to_json("ultrachat_chunk_eval.jsonl", orient="records", lines=True)
Reformat dataset
If you upload this ultrachat_chunk_train.jsonl to Mistral API, you might encounter an error message “Invalid file format” due to data formatting issues. To reformat the data into the correct format, you can download the reformat_data.py script and use it to validate and reformat both the training and evaluation data:
# download the validation and reformat script
wget https://raw.githubusercontent.com/mistralai/mistral-finetune/main/utils/reformat_data.py
# validate and reformat the training data
python reformat_data.py ultrachat_chunk_train.jsonl
# validate the reformat the eval data
python reformat_data.py ultrachat_chunk_eval.jsonl
This reformat_data.py script is tailored for the UltraChat data and may not be universally applicable to other datasets. Please modify this script and reformat your data accordingly.
After running the script, few cases were removed from the training data.
Skip 3674th sample
Skip 9176th sample
Skip 10559th sample
Skip 13293th sample
Skip 13973th sample
Skip 15219th sample
Let’s inspect one of these cases. There are two issues with this use case:
- one of the assistant messages is an empty string;
- the last message is not an assistant message.

Upload dataset
We can then upload both the training data and evaluation data to the Mistral Client, making them available for use in fine-tuning jobs.
- python
- javascript
- curl
import os
from mistralai.client import MistralClient
api_key = os.environ.get("MISTRAL_API_KEY")
client = MistralClient(api_key=api_key)
with open("ultrachat_chunk_train.jsonl", "rb") as f:
ultrachat_chunk_train = client.files.create(file=("ultrachat_chunk_train.jsonl", f))
with open("ultrachat_chunk_eval.jsonl", "rb") as f:
ultrachat_chunk_eval = client.files.create(file=("ultrachat_chunk_eval.jsonl", f))
import MistralClient from '@mistralai/mistralai';
const apiKey = process.env.MISTRAL_API_KEY;
const client = new MistralClient(apiKey);
const file = fs.readFileSync('ultrachat_chunk_train.jsonl');
const ultrachat_chunk_train = await client.files.create({ file });
const file = fs.readFileSync('ultrachat_chunk_eval.jsonl');
const ultrachat_chunk_eval = await client.files.create({ file });
curl https://api.mistral.ai/v1/files \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-F purpose="fine-tune" \
-F file="@ultrachat_chunk_train.jsonl"
curl https://api.mistral.ai/v1/files \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-F purpose="fine-tune" \
-F file="@ultrachat_chunk_eval.jsonl"
Example output:
Note that you will need the file IDs for the next steps.
{
"id": "66f96d02-8b51-4c76-a5ac-a78e28b2584f",
"object": "file",
"bytes": 140893645,
"created_at": 1717164199,
"filename": "ultrachat_chunk_train.jsonl",
"purpose": "fine-tune"
}
{
"id": "84482011-dfe9-4245-9103-d28b6aef30d4",
"object": "file",
"bytes": 7247934,
"created_at": 1717164200,
"filename": "ultrachat_chunk_eval.jsonl",
"purpose": "fine-tune"
}
Create a fine-tuning job
Next, we can create a fine-tuning job:
- python
- javascript
- curl
from mistralai.models.jobs import TrainingParameters
created_jobs = client.jobs.create(
model="open-mistral-7b",
training_files=[ultrachat_chunk_train.id],
validation_files=[ultrachat_chunk_eval.id],
hyperparameters=TrainingParameters(
training_steps=10,
learning_rate=0.0001,
)
)
created_jobs
const createdJob = await client.jobs.create({
model: 'open-mistral-7b',
trainingFiles: [ultrachat_chunk_train.id],
validationFiles: [ultrachat_chunk_eval.id],
hyperparameters: {
trainingSteps: 10,
learningRate: 0.0001,
},
});
curl https://api.mistral.ai/v1/fine_tuning/jobs \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--data '{
"model": "open-mistral-7b",
"training_files": [
"<uuid>"
],
"validation_files": [
"<uuid>"
],
"hyperparameters": {
"training_steps": 10,
"learning_rate": 0.0001
}
}'
Example output:
{
"id": "25d7efe6-6303-474f-9739-21fb0fccd469",
"hyperparameters": {
"training_steps": 10,
"learning_rate": 0.0001
},
"fine_tuned_model": null,
"model": "open-mistral-7b",
"status": "QUEUED",
"job_type": "FT",
"created_at": 1717170356,
"modified_at": 1717170357,
"training_files": [
"66f96d02-8b51-4c76-a5ac-a78e28b2584f"
],
"validation_files": [
"84482011-dfe9-4245-9103-d28b6aef30d4"
],
"object": "job",
"integrations": []
}
Use a fine-tuned model
When a fine-tuned job is finished, you will be able to see the fine-tuned model name via retrieved_jobs.fine_tuned_model. Then you can use our chat endpoint to chat with the fine-tuned model:
- python
- javascript
- curl
from mistralai.models.chat_completion import ChatMessage
chat_response = client.chat(
model=retrieved_job.fine_tuned_model,
messages=[ChatMessage(role='user', content='What is the best French cheese?')]
)
const chatResponse = await client.chat({
model: retrievedJob.fine_tuned_model,
messages: [{role: 'user', content: 'What is the best French cheese?'}],
});
curl "https://api.mistral.ai/v1/chat/completions" \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--data '{
"model": "ft:open-mistral-7b:daf5e488:20240430:c1bed559",
"messages": [{"role": "user", "content": "Who is the most renowned French painter?"}]
}'
Analyze and evaluate fine-tuned model
When we retrieve a model, we get the following metrics every 10% of the progress with a minimum of 10 steps in between:
- Training loss: the error of the model on the training data, indicating how well the model is learning from the training set.
- Validation loss: the error of the model on the validation data, providing insight into how well the model is generalizing to unseen data.
- Validation token accuracy: the percentage of tokens in the validation set that are correctly predicted by the model.
Both validation loss and validation token accuracy serve as essential indicators of the model's overall performance, helping to assess its ability to generalize and make accurate predictions on new data.
- python
- javascript
- curl
# Retrieve a jobs
retrieved_jobs = client.jobs.retrieve(created_jobs.id)
print(retrieved_jobs)
// Retrieve a job
const retrievedJob = await client.jobs.retrieve({ jobId: createdJob.id });
# Retrieve a job
curl https://api.mistral.ai/v1/fine_tuning/jobs/<jobid> \
--header "Authorization: Bearer $MISTRAL_API_KEY" \
--header 'Content-Type: application/json'
Example output when we run 100 steps:
{
"id": "2813b7e6-c511-43ac-a16a-1a54a5b884b2",
"hyperparameters": {
"training_steps": 100,
"learning_rate": 0.0001
},
"fine_tuned_model": "ft:open-mistral-7b:57d37e6c:20240531:2813b7e6",
"model": "open-mistral-7b",
"status": "SUCCESS",
"job_type": "FT",
"created_at": 1717172592,
"modified_at": 1717173491,
"training_files": [
"66f96d02-8b51-4c76-a5ac-a78e28b2584f"
],
"validation_files": [
"84482011-dfe9-4245-9103-d28b6aef30d4"
],
"object": "job",
"integrations": [],
"events": [
{
"name": "status-updated",
"data": {
"status": "SUCCESS"
},
"created_at": 1717173491
},
{
"name": "status-updated",
"data": {
"status": "RUNNING"
},
"created_at": 1717172594
},
{
"name": "status-updated",
"data": {
"status": "QUEUED"
},
"created_at": 1717172592
}
],
"checkpoints": [
{
"metrics": {
"train_loss": 0.816135,
"valid_loss": 0.819697,
"valid_mean_token_accuracy": 1.765035
},
"step_number": 100,
"created_at": 1717173470
},
{
"metrics": {
"train_loss": 0.84643,
"valid_loss": 0.819768,
"valid_mean_token_accuracy": 1.765122
},
"step_number": 90,
"created_at": 1717173388
},
{
"metrics": {
"train_loss": 0.816602,
"valid_loss": 0.820234,
"valid_mean_token_accuracy": 1.765692
},
"step_number": 80,
"created_at": 1717173303
},
{
"metrics": {
"train_loss": 0.775537,
"valid_loss": 0.821105,
"valid_mean_token_accuracy": 1.766759
},
"step_number": 70,
"created_at": 1717173217
},
{
"metrics": {
"train_loss": 0.840297,
"valid_loss": 0.822249,
"valid_mean_token_accuracy": 1.76816
},
"step_number": 60,
"created_at": 1717173131
},
{
"metrics": {
"train_loss": 0.823884,
"valid_loss": 0.824598,
"valid_mean_token_accuracy": 1.771041
},
"step_number": 50,
"created_at": 1717173045
},
{
"metrics": {
"train_loss": 0.786473,
"valid_loss": 0.827982,
"valid_mean_token_accuracy": 1.775201
},
"step_number": 40,
"created_at": 1717172960
},
{
"metrics": {
"train_loss": 0.8704,
"valid_loss": 0.835169,
"valid_mean_token_accuracy": 1.784066
},
"step_number": 30,
"created_at": 1717172874
},
{
"metrics": {
"train_loss": 0.880803,
"valid_loss": 0.852521,
"valid_mean_token_accuracy": 1.805653
},
"step_number": 20,
"created_at": 1717172788
},
{
"metrics": {
"train_loss": 0.803578,
"valid_loss": 0.914257,
"valid_mean_token_accuracy": 1.884598
},
"step_number": 10,
"created_at": 1717172702
}
]
}
Integration with Weights and Biases
We can also offer support for integration with Weights & Biases (W&B) to monitor and track various metrics and statistics associated with our fine-tuning jobs. To enable integration with W&B, you will need to create an account with W&B and add your W&B information in the “integrations” section in the job creation request:
from mistralai.models.jobs import WandbIntegrationIn, TrainingParameters
wandb_api_key = os.environ.get("WANDB_API_KEY")
created_jobs = client.jobs.create(
model="open-mistral-7b",
training_files=[ultrachat_chunk_train.id],
validation_files=[ultrachat_chunk_eval.id],
hyperparameters=TrainingParameters(
training_steps=300,
learning_rate=0.0001,
),
integrations=[
WandbIntegrationIn(
project="test_api",
run_name="test",
api_key=wandb_api_key,
).dict()
]
)
Here are the screenshots of the W&B dashboard showing the information of our fine-tuning job.
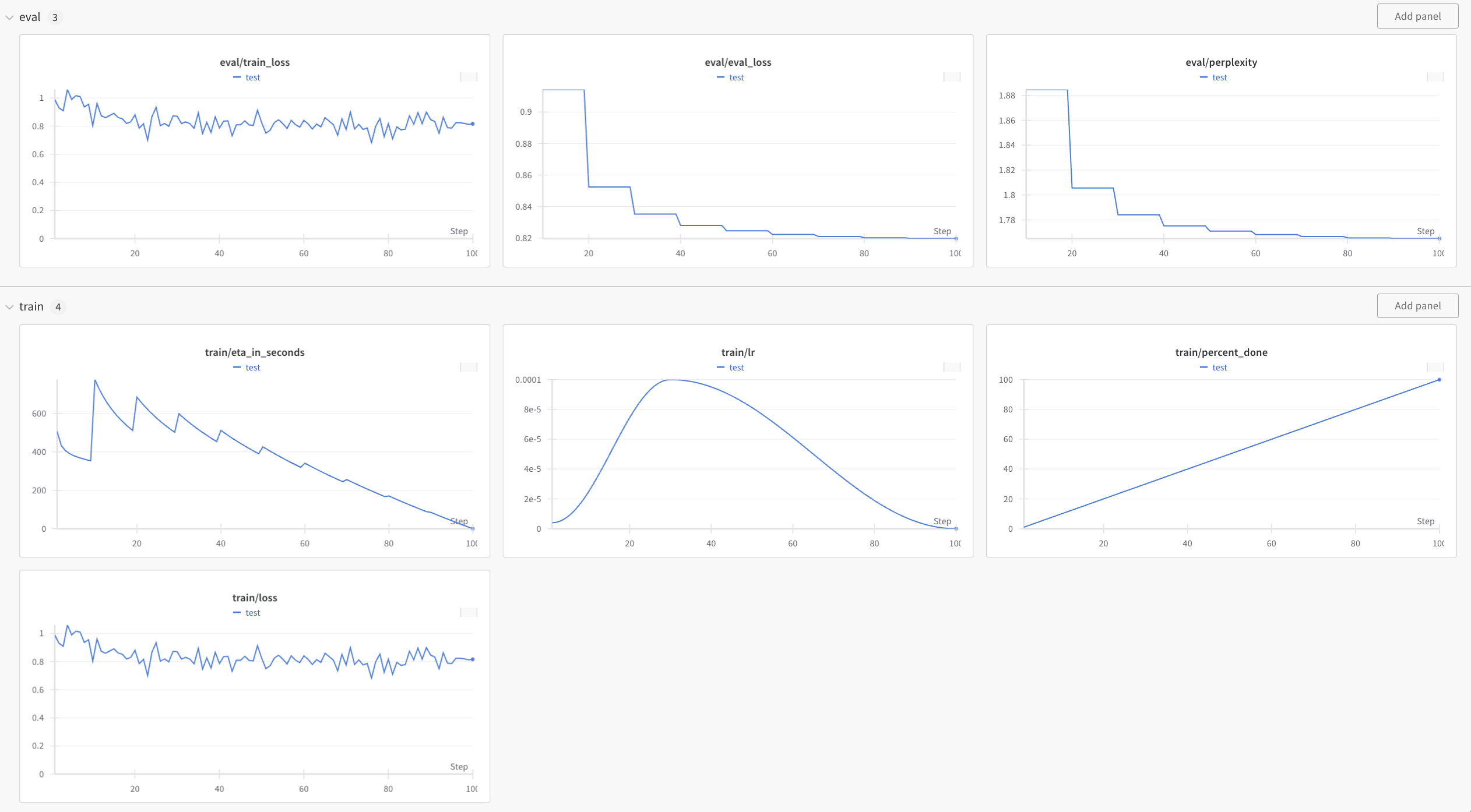
End-to-end example with open-source mistral-finetune
We have also open sourced fine-tuning codebase mistral-finetune allowing you to fine-tune Mistral’s open-weights models (Mistral 7B, Mixtral 8x7B, Mixtral 8x22B).
To see an end-to-end example of how to install mistral-finetune, prepare and validate your dataset, define your training configuration, fine-tune using Mistral-LoRA, and run inference, please refer to the README file provided in the Mistral-finetune repo: https://github.com/mistralai/mistral-finetune/tree/main or follow this example:
FAQ
How to validate data format?
-
Mistral API: We currently validate each file when you upload the dataset.
-
mistral-finetune: You can run the data validation script to validate the data and run the reformat data script to reformat the data to the right format:# download the reformat script
wget https://raw.githubusercontent.com/mistralai/mistral-finetune/main/utils/reformat_data.py
# download the validation script
wget https://raw.githubusercontent.com/mistralai/mistral-finetune/main/utils/validate_data.py
# reformat data
python reformat_data.py data.jsonl
# validate data
python validate_data.py data.jsonlHowever, it's important to note that these scripts might not detect all problematic cases. Therefore, you may need to manually validate and correct any unique edge cases in your data.
What's the size limit of the training data?
While the size limit for an individual training data file is 512MB, there's no limitation on the number of files you can upload. You can upload multiple files and reference them when creating the job.
What's the size limit of the validation data?
The size limit for the validation data is 1MB. As a rule of thumb:
validation_set_max_size = min(1MB, 5% of training data)
How many epochs are in the training process?
A general rule of thumb is: Num epochs = max_steps / file_of_training_jsonls_in_MB. For instance, if your training file is 100MB and you set max_steps=1000, the training process will roughly perform 10 epochs.
Where can I find information on ETA / number of tokens / number of passes over each files?
Mistral API: Use the dry_run=True argument.
dry_run_job = await client.jobs.create(
model="open-mistral-7b",
training_files=[training_file.id],
hyperparameters=TrainingParameters(
training_steps=10,
learning_rate=0.0001,
),
dry_run=True,
)
print(dry_run_job)
mistral-finetune: You can use the following script to find out: https://github.com/mistralai/mistral-finetune/blob/main/utils/validate_data.py. This script accepts a .yaml training file as input and returns the number of tokens the model is being trained on.
What is the recommended learning rate?
For LoRA fine-tuning, we recommended 1e-4 (default) or 1e-5.
Note that the learning rate we define is the peak learning rate, instead of a flat learning rate. The learning rate follows a linear warmup and cosine decay schedule. During the warmup phase, the learning rate is linearly increased from a small initial value to a larger value over a certain number of training steps. After the warmup phase, the learning rate is decayed using a cosine function.
Is the fine-tuning API compatible with OpenAI data format?
Yes, we support OpenAI format.
What if my file size is larger than 500MB and I get the error message 413 Request Entity Too Large?
You can split your data file into chunks. Here is an example:
Details
import json
from datasets import load_dataset
# get data from hugging face
ds = load_dataset("HuggingFaceH4/ultrachat_200k",split="train_gen")
# save data into .jsonl. This file is about 1.3GB
with open('train.jsonl', 'w') as f:
for line in ds:
json.dump(line, f)
f.write('\n')
# reformat data
!wget https://raw.githubusercontent.com/mistralai/mistral-finetune/main/utils/reformat_data.py
!python reformat_data.py train.jsonl
# Split file into three chunks
input_file = "train.jsonl"
output_files = ["train_1.jsonl", "train_2.jsonl", "train_3.jsonl"]
# open the output files
output_file_objects = [open(file, "w") for file in output_files]
# counter for output files
counter = 0
with open(input_file, "r") as f_in:
# read the input file line by line
for line in f_in:
# parse the line as JSON
data = json.loads(line)
# write the data to the current output file
output_file_objects[counter].write(json.dumps(data) + "\n")
# increment the counter
counter = (counter + 1) % 3
# close the output files
for file in output_file_objects:
file.close()
# now you should see three jsonl files under 500MB