[2' read]
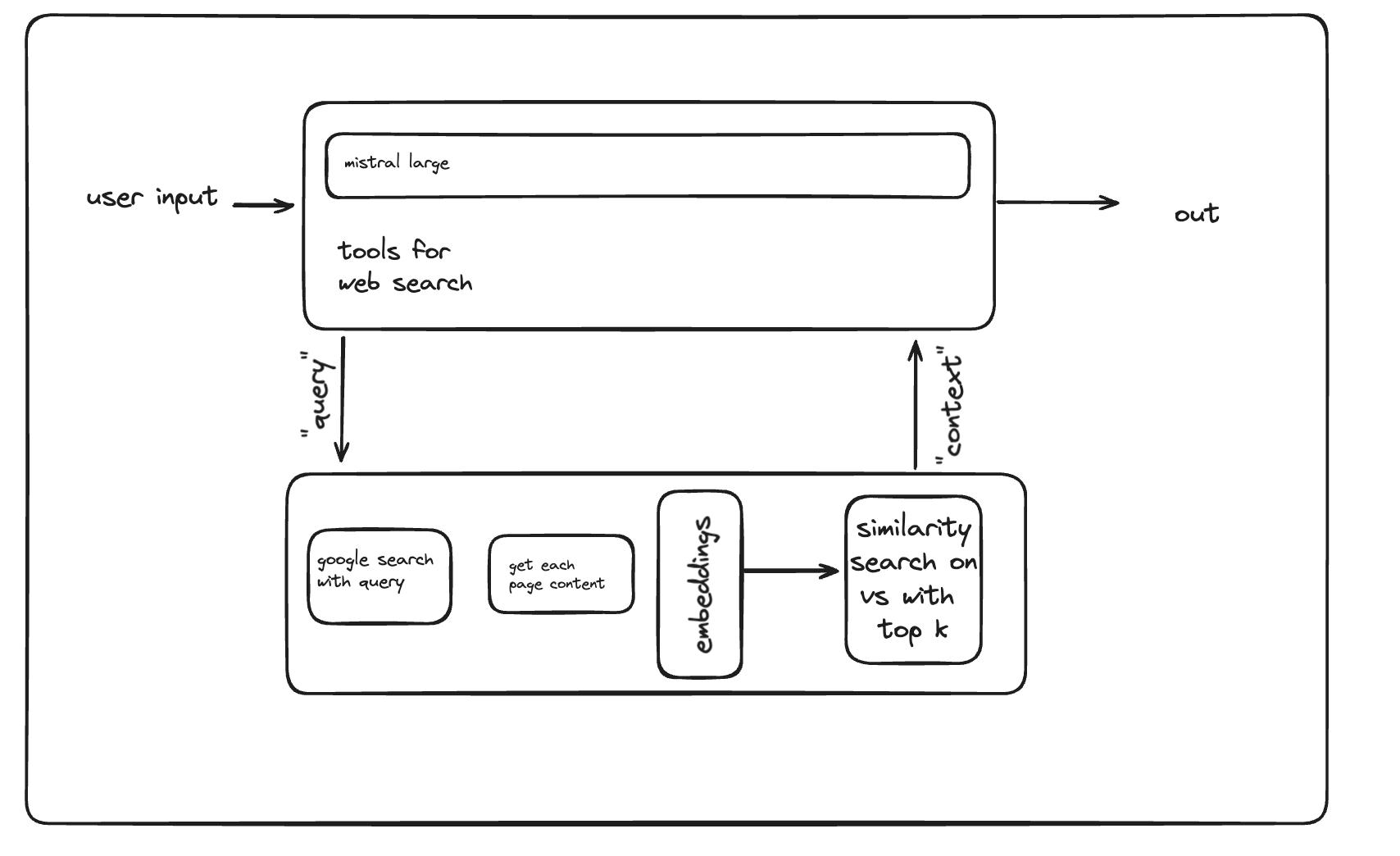
Mistral AI search engine
RAGSearch engine
Mistral AI search engine
!pip install aiohttp==3.9.5 beautifulsoup4==4.12.3 faiss_cpu==1.8.0 mistralai==0.4.0 nest_asyncio==1.6.0 numpy==1.26.4 pandas==2.2.2 python-dotenv==1.0.1 requests==2.32.3
from dotenv import load_dotenv
import os
load_dotenv() # load environment variables from .env file
MISTRAL_API_KEY = os.getenv("MISTRAL_API_KEY")Scraper Definitions
import aiohttp
import asyncio
import nest_asyncio
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
import requests
import re
import pandas as pd
import faiss
import numpy as np
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
# Apply the nest_asyncio patch
nest_asyncio.apply()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
total_results_to_fetch = 10 # total number of results to fetch
chunk_size = 1000 # size of each text chunk
dataframe_out_path = 'temp.csv'
faiss_index_path = 'faiss_index.index'
mistral_api_key = MISTRAL_API_KEY # replace with your actual API key
client = MistralClient(api_key=mistral_api_key)
async def fetch(session, url, params=None):
async with session.get(url, params=params, headers=headers, timeout=30) as response:
return await response.text()
async def fetch_page(session, params, page_num, results):
print(f"Fetching page: {page_num}")
params["start"] = (page_num - 1) * params["num"]
html = await fetch(session, "https://www.google.com/search", params)
soup = BeautifulSoup(html, 'html.parser')
for result in soup.select(".tF2Cxc"):
if len(results) >= total_results_to_fetch:
break
title = result.select_one(".DKV0Md").text
links = result.select_one(".yuRUbf a")["href"]
results.append({
"title": title,
"links": links
})
async def fetch_content(session, url):
async with session.get(url, headers=headers, timeout=30) as response:
return await response.text()
async def fetch_all_content(urls):
async with aiohttp.ClientSession() as session:
tasks = [fetch_content(session, url) for url in urls]
return await asyncio.gather(*tasks)
def get_all_text_from_url(url):
response = requests.get(url, headers=headers, timeout=30)
soup = BeautifulSoup(response.text, 'html.parser')
for script in soup(["script", "style"]):
script.extract()
text = soup.get_text()
lines = (line.strip() for line in text.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = '\n'.join(chunk for chunk in chunks if chunk)
return text
def split_text_into_chunks(text, chunk_size):
sentences = re.split(r'(?<=[.!?]) +', text)
chunks = []
current_chunk = []
for sentence in sentences:
if sum(len(s) for s in current_chunk) + len(sentence) + 1 > chunk_size:
chunks.append(' '.join(current_chunk))
current_chunk = [sentence]
else:
current_chunk.append(sentence)
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
async def process_text_content(texts, chunk_size):
loop = asyncio.get_event_loop()
tasks = [loop.run_in_executor(None, split_text_into_chunks, text, chunk_size) for text in texts]
return await asyncio.gather(*tasks)
async def get_embeddings_from_mistral(client, text_chunks):
response = client.embeddings(model="mistral-embed", input=text_chunks)
return [embedding.embedding for embedding in response.data]
async def fetch_and_process_data(search_query):
params = {
"q": search_query, # query example
"hl": "en", # language
"gl": "uk", # country of the search, UK -> United Kingdom
"start": 0, # number page by default up to 0
"num": 10 # parameter defines the maximum number of results to return per page.
}
async with aiohttp.ClientSession() as session:
page_num = 0
results = []
while len(results) < total_results_to_fetch:
page_num += 1
await fetch_page(session, params, page_num, results)
urls = [result['links'] for result in results]
with ThreadPoolExecutor(max_workers=10) as executor:
loop = asyncio.get_event_loop()
texts = await asyncio.gather(
*[loop.run_in_executor(executor, get_all_text_from_url, url) for url in urls]
)
chunks_list = await process_text_content(texts, chunk_size)
embeddings_list = []
for chunks in chunks_list:
embeddings = await get_embeddings_from_mistral(client, chunks)
embeddings_list.append(embeddings)
data = []
for i, result in enumerate(results):
if i >= len(embeddings_list):
print(f"Error: No embeddings returned for result {i}")
continue
for j, chunk in enumerate(chunks_list[i]):
if j >= len(embeddings_list[i]):
print(f"Error: No embedding returned for chunk {j} of result {i}")
continue
data.append({
'title': result['title'],
'url': result['links'],
'chunk': chunk,
'embedding': embeddings_list[i][j]
})
df = pd.DataFrame(data)
df.to_csv(dataframe_out_path, index=False)
# FAISS indexing
dimension = len(embeddings_list[0][0]) # assuming all embeddings have the same dimension
index = faiss.IndexFlatL2(dimension)
embeddings = np.array([entry['embedding'] for entry in data], dtype=np.float32)
index.add(embeddings)
faiss.write_index(index, faiss_index_path)
await fetch_and_process_data("What is the latest news about apple and openai?")
little embeddings and vector store creation
def query_vector_store(query_embedding, k=5):
"""
Query the FAISS vector store and return the text results along with metadata.
:param query_embedding: The embedding to query with.
:param k: Number of nearest neighbors to retrieve.
:return: List of dictionaries containing text results and metadata of the k nearest neighbors.
"""
# Load the index
index = faiss.read_index(faiss_index_path)
# Ensure the query embedding is a numpy array with the correct shape
if not isinstance(query_embedding, np.ndarray):
query_embedding = np.array(query_embedding, dtype=np.float32)
if query_embedding.ndim == 1:
query_embedding = np.expand_dims(query_embedding, axis=0)
# Query the index
distances, indices = index.search(query_embedding, k)
# Load the dataframe
df = pd.read_csv(dataframe_out_path)
# Retrieve the text results and metadata
results = []
for idx in indices[0]:
result = {
'title': df.iloc[idx]['title'],
'url': df.iloc[idx]['url'],
'chunk': df.iloc[idx]['chunk']
}
results.append(result)
return results
def query_embeddings(texts):
"""
Convert text to embeddings using Mistral AI API.
:param api_key: Your Mistral API key.
:param texts: List of texts to convert to embeddings.
:return: List of embeddings.
"""
client = MistralClient(api_key=MISTRAL_API_KEY)
response = client.embeddings(model="mistral-embed", input=[texts])
return [embedding.embedding for embedding in response.data]
embeddings = query_embeddings("AGI")
results = query_vector_store(embeddings[0], k=5)
results
tools definition
nest_asyncio.apply()
tools = [
{
"type": "function",
"function": {
"name": "mistral_web_search",
"description": "Fetch and process data from Google search based on a query, store results in FAISS vector store, and retrieve results.",
"parameters": {
"type": "object",
"properties": {
"search_query": {
"type": "string",
"description": "The search query to use for fetching data from Google search."
}
},
"required": ["search_query"]
},
},
},
]
def mistral_web_search(search_query: str):
async def run_search():
await fetch_and_process_data(search_query)
embeddings = query_embeddings(search_query)
results_ = query_vector_store(embeddings[0], k=5)
return results_
return asyncio.run(run_search())
search_query = "mistral and openai"
results = mistral_web_search(search_query)
print(results)
""" little helper function to extract only the texts """
def tools_to_str(tools_output: list) -> str:
return '\n'.join([tool['chunk'] for tool in tools_output])
tools_to_str(mistral_web_search(search_query))import functools
names_to_functions = {
'mistral_web_search': functools.partial(mistral_web_search),
}chat
messages = [
ChatMessage(role="user", content="What happend during apple WWDC 2024?"),
]
model = "mistral-large-latest"
client = MistralClient(api_key=MISTRAL_API_KEY)
response = client.chat(model=model, messages=messages, tools=tools, tool_choice="any")
responsemessages.append(response.choices[0].message)import json
tool_call = response.choices[0].message.tool_calls[0]
function_name = tool_call.function.name
function_params = json.loads(tool_call.function.arguments)
print("\nfunction_name: ", function_name, "\nfunction_params: ", function_params)function_result = tools_to_str(names_to_functions[function_name](**function_params))
function_resultmessages.append(ChatMessage(role="tool", name=function_name, content=function_result, tool_call_id=tool_call.id))
response = client.chat(model=model, messages=messages)
response.choices[0].message.content
Chat in a chain (cleaner user experience)
messages = []
while True:
input_ = input("Ask: ")
messages.append(ChatMessage(role="user", content=input_))
response = client.chat(model=model, messages=messages, tools=tools, tool_choice="any")
messages.append(response.choices[0].message)
print(response.choices[0].message.content)
tool_call = response.choices[0].message.tool_calls[0]
function_name = tool_call.function.name
function_params = json.loads(tool_call.function.arguments)
function_result_raw = names_to_functions[function_name](**function_params)
print("sources: ", [f"{source['title']} - {source['url']}" for source in function_result_raw])
function_result_text = tools_to_str(function_result_raw)
messages.append(ChatMessage(role="tool", name=function_name, content=function_result_text, tool_call_id=tool_call.id))
response = client.chat(model=model, messages=messages)
final_response = response.choices[0].message.content
print(final_response)