In this cookbook, we will explore classification for intent detection and classification using our Classifier Factory.
To keep things straightforward, we will concentrate on a particular example that involves single-target classification.
Dataset
We will use a subset of the mteb/amazon_massive_intent dataset. This subset includes an intent for different user requests.
Subset
Let's download and prepare the subset. We will install the datasets library and load the dataset.
%%capture
!pip install datasets# @title Loading and preparing subset
%%capture
# Import necessary libraries
from datasets import load_dataset
import pandas as pd
from sklearn.model_selection import train_test_split
# Load the entire amazon_massive_intent dataset
dataset = load_dataset("mteb/amazon_massive_intent")
# Filter for English language samples
train_samples = dataset["train"].filter(lambda x: x["lang"] == "en")
# Select only the required columns
train_samples = train_samples.select_columns(["text", "label_text"])
# Convert to pandas DataFrame
train_df = pd.DataFrame(train_samples)
# Function to remove labels with less than 200 samples and limit each label to 600 samples
def process_labels(df, min_samples=200, max_samples=600):
label_counts = df["label_text"].value_counts()
labels_to_keep = label_counts[label_counts >= min_samples].index
df = df[df["label_text"].isin(labels_to_keep)]
# Limit each label to max_samples
balanced_df = pd.DataFrame()
for label in labels_to_keep:
label_samples = df[df["label_text"] == label].sample(
n=min(len(df[df["label_text"] == label]), max_samples), random_state=42
)
balanced_df = pd.concat([balanced_df, label_samples])
return balanced_df
# Process labels in the training dataset
train_df = process_labels(train_df)
# Split the training data into train, validation, and test sets
train_df, temp_df = train_test_split(
train_df, test_size=0.2, random_state=42, stratify=train_df["label_text"]
)
validation_df, test_df = train_test_split(
temp_df, test_size=0.5, random_state=42, stratify=temp_df["label_text"]
)# Display the test DataFrame to verify
test_df# @title Data distribution
import matplotlib.pyplot as plt
from collections import Counter
# Function to count the number of samples for each label
def count_labels(samples):
labels = [sample["label_text"] for sample in samples.to_dict("records")]
return Counter(labels)
# Count labels for each dataset
train_label_counts = count_labels(train_df)
validation_label_counts = count_labels(validation_df)
test_label_counts = count_labels(test_df)
# Create a single figure with subplots for bar charts
fig, axes = plt.subplots(3, 1, figsize=(12, 18))
# Plot the bar charts for label distribution
def plot_label_distribution(ax, label_counts, title):
# Sort labels by count in descending order
sorted_labels, sorted_counts = zip(
*sorted(label_counts.items(), key=lambda x: x[1], reverse=True)
)
ax.bar(sorted_labels, sorted_counts, color="skyblue")
ax.set_ylabel("Count")
ax.set_title(title)
ax.tick_params(axis="x", rotation=45)
# Plot label distribution for each dataset
plot_label_distribution(
axes[0], train_label_counts, "Train Samples (Label Distribution)"
)
plot_label_distribution(
axes[1], validation_label_counts, "Validation Samples (Label Distribution)"
)
plot_label_distribution(axes[2], test_label_counts, "Test Samples (Label Distribution)")
plt.tight_layout()
plt.show()Format Data
Now that we have loaded our dataset, we will convert it to the proper desired format to upload for training.
The data will be converted to a JSONL format as follows:
{"text": "place a birthday party with ale ross and amy in my calendar", "labels": {"intent": "calendar_set"}}
{"text": "new music tracks", "labels": {"intent": "play_music"}}
{"text": "get me the details of upcoming oscar two thousand and seventeen", "labels": {"intent": "calendar_query"}}
{"text": "is there any event today in my calendar", "labels": {"intent": "calendar_query"}}
{"text": "send email to mommy that i'll be going the party", "labels": {"intent": "email_sendemail"}}
...With an example of a label being:
"labels": {
"intent": "email_sendemail"
}For single-target classification.
from tqdm import tqdm
import json
def dataset_to_jsonl(dataset, output_file):
# Extract the unique labels from the dataset
unique_labels = dataset["label_text"].unique()
# Open the output file in write mode
with open(output_file, "w") as f:
# Iterate over each row in the dataset
for _, row in tqdm(dataset.iterrows(), total=dataset.shape[0]):
# Extract the text and label from the row
text = row["text"]
intent = row["label_text"]
# Create the JSON object with the desired structure
json_object = {"text": text, "labels": {"intent": intent}}
# Write the JSON object to the file as a JSON line
f.write(json.dumps(json_object) + "\n")
# Save files
dataset_to_jsonl(train_df, "train.jsonl")
dataset_to_jsonl(validation_df, "validation.jsonl")
dataset_to_jsonl(test_df, "test.jsonl")The data was converted and saved properly. We can now train our model.
Training
There are two methods to train the model: either upload and train via la platforme or via the API.
First, we need to install mistralai.
%%capture
!pip install mistralaiAnd setup our client, you can create an API key here.
from mistralai import Mistral
import os
# Set the API key for Mistral
api_key = "API_KEY"
# Set your Weights and Biases key
wandb_key = "WANDB_KEY"
# Initialize the Mistral client
client = Mistral(api_key=api_key)We will upload 2 files, the training set and the validation set ( optional ) that will be used for validation loss.
# Upload the training data
training_data = client.files.upload(
file={
"file_name": "train.jsonl",
"content": open("train.jsonl", "rb"),
}
)
# Upload the validation data
validation_data = client.files.upload(
file={
"file_name": "validation.jsonl",
"content": open("validation.jsonl", "rb"),
}
)With the data uploaded, we can create a job.
We allow users to keep track of aconsiderable amount of metrics via our Weights and Biases integration that we strongly recommend, you can make use of it by providing the project name and your key.
# Create a fine-tuning job
created_job = client.fine_tuning.jobs.create(
model="ministral-3b-latest",
job_type="classifier",
training_files=[{"file_id": training_data.id, "weight": 1}],
validation_files=[validation_data.id],
hyperparameters={"training_steps": 100, "learning_rate": 0.00004},
auto_start=False,
integrations=[
{
"project": "intent-classifier",
"api_key": wandb_key,
}
]
)
print(json.dumps(created_job.model_dump(), indent=4))Once the job is created, we can review details such as the number of epochs and other relevant information. This allows us to make informed decisions before initiating the job.
We'll retrieve the job and wait for it to complete the validation process before starting. This validation step ensures the job is ready to begin.
# Retrieve the job details
retrieved_job = client.fine_tuning.jobs.get(job_id=created_job.id)
print(json.dumps(retrieved_job.model_dump(), indent=4))
import time
from IPython.display import clear_output
# Wait for the job to be validated
while retrieved_job.status not in ["VALIDATED"]:
retrieved_job = client.fine_tuning.jobs.get(job_id=created_job.id)
clear_output(wait=True) # Clear the previous output (User Friendly)
print(json.dumps(retrieved_job.model_dump(), indent=4))
time.sleep(1)We can now run the job.
# Start the fine-tuning job
client.fine_tuning.jobs.start(job_id=created_job.id)
# Retrieve the job details again
retrieved_job = client.fine_tuning.jobs.get(job_id=created_job.id)
print(json.dumps(retrieved_job.model_dump(), indent=4))The job is now starting. Let's keep track of the status and print the information.
We highly recommend making use of our Weights and Biases integration to keep track of multiple metrics.
WANDB
Training:
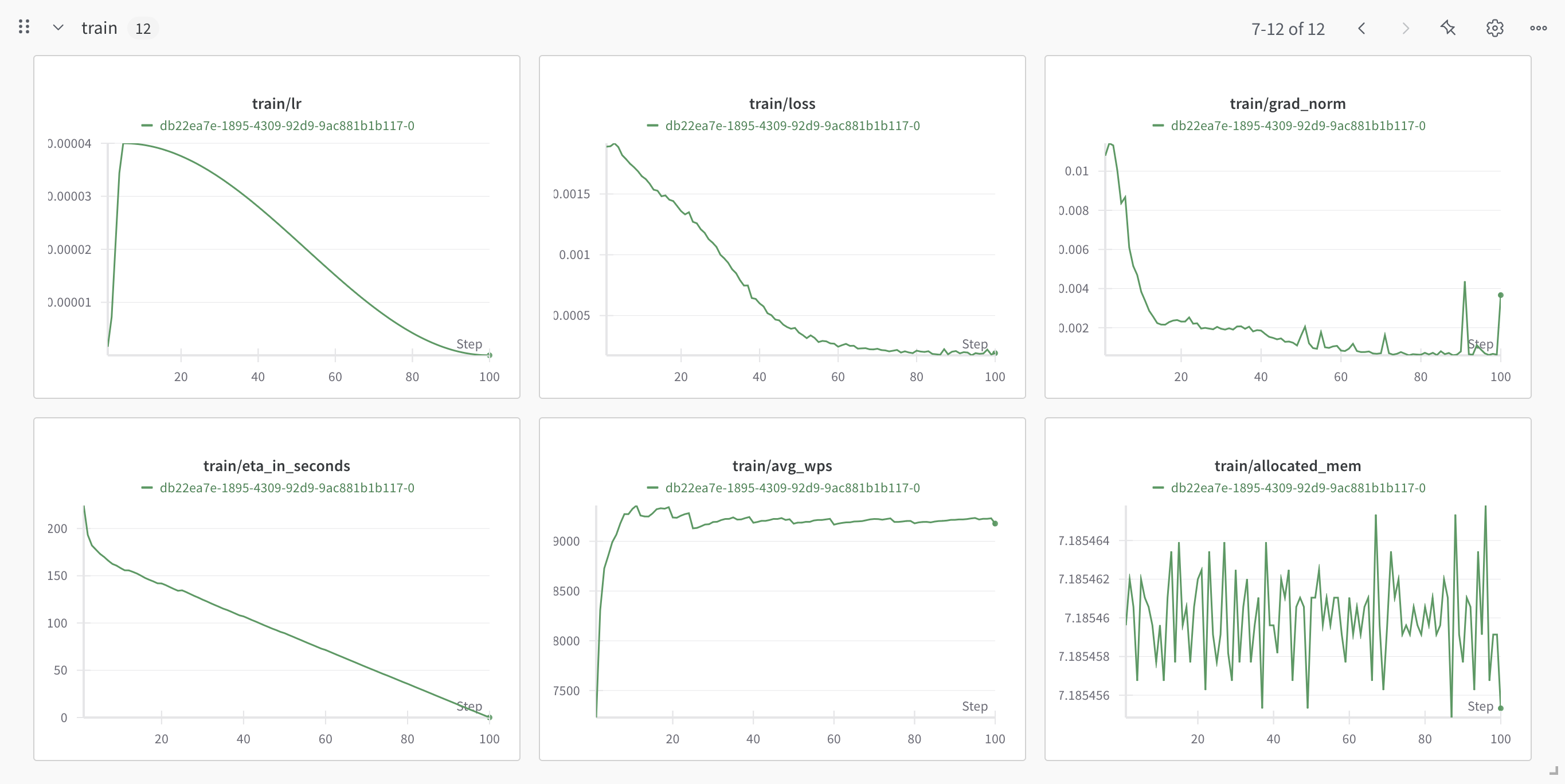
Eval/Validation:
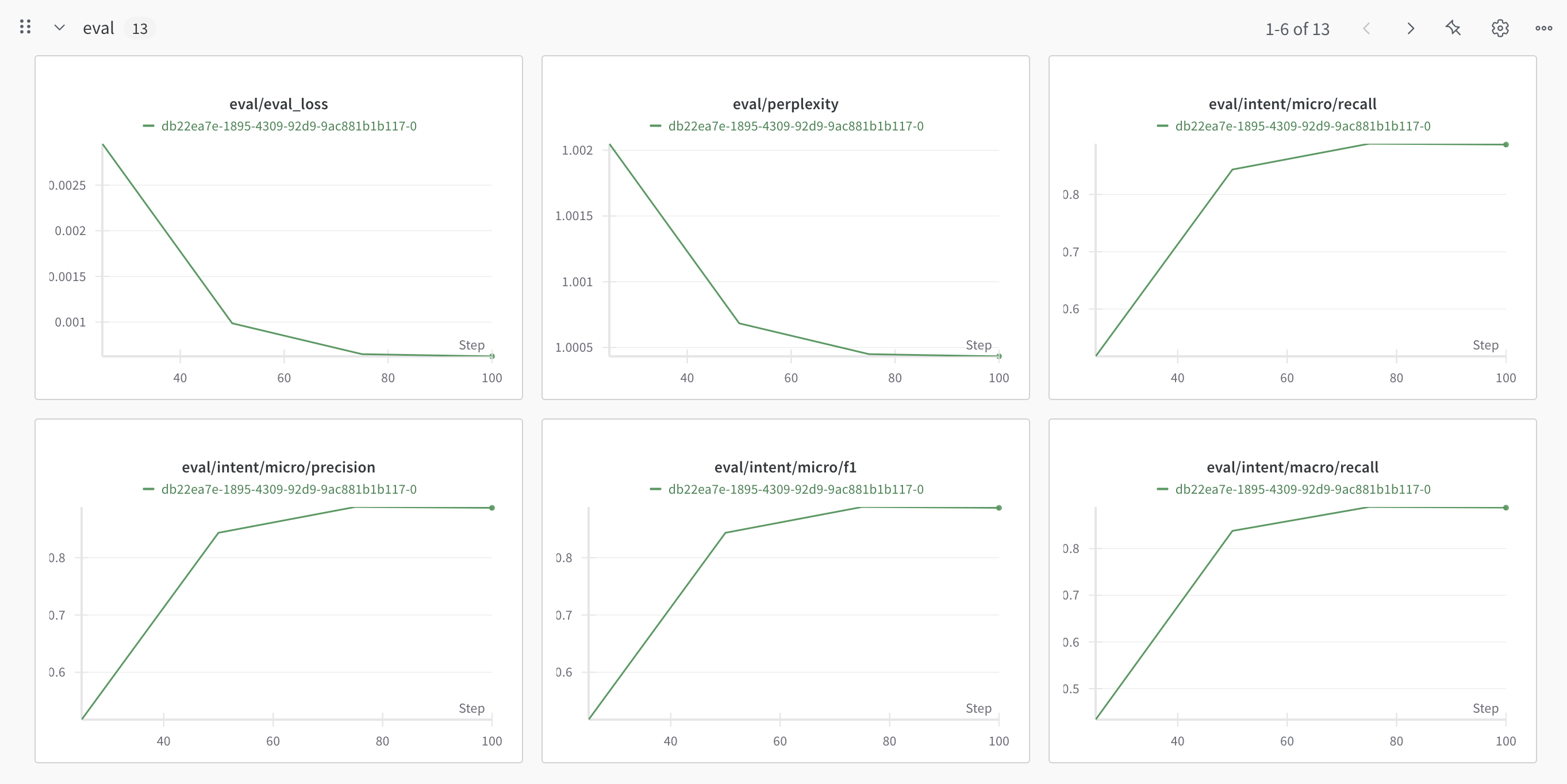
# Wait for the job to complete
while retrieved_job.status in ["QUEUED", "RUNNING"]:
retrieved_job = client.fine_tuning.jobs.get(job_id=created_job.id)
clear_output(wait=True) # Clear the previous output (User Friendly)
job_info = json.dumps(retrieved_job.model_dump(), indent=4)
if len(job_info) > 10000:
print(job_info[:5000] + "\n[...]\n" + job_info[-5000:])
else:
print(job_info)
time.sleep(5)Inference
Our model is trained and ready for use! Let's test it on a sample from our test set!
# Load the test samples
with open("test.jsonl", "r") as f:
test_samples = [json.loads(l) for l in f.readlines()]
# Classify the first test sample
classifier_response = client.classifiers.classify(
model=retrieved_job.fine_tuned_model,
inputs=[test_samples[0]["text"]],
)
print("Text:", test_samples[0]["text"])
print("Classifier Response:", json.dumps(classifier_response.model_dump(), indent=4))The score with the highest result is weather_query, with an over 99% score!
There you have it: a simple guide on how to train your own classifier and use our batch inference.
For a more specific multi-label classifier, visit this cookbook.
For a more product focused in-depth guide on both multi-target, with an evaluation comparison between LLMs and our classifier, visit this cookbook.