Introduction
The Multi Agent Workflow For Recruitment is an automated system designed to help streamline the hiring process through specialized AI agents working in harmony to improve candidate evaluation, save time and resources, and improve overall hiring outcomes.
The Problem
Today's recruitment landscape faces three critical challenges:
-
Overwhelming Volume: Recruiters struggle to efficiently process large numbers of applications, often missing qualified candidates.
-
Manual Inefficiency: Traditional resume screening is time-consuming, inconsistent, and vulnerable to bias.
-
Poor Candidate Experience: Slow response times and fragmented communication damage employer brand and lose top talent.
Why This Matters
Ineffective recruitment directly impacts business outcomes through:
- Reduced Performance: Missing qualified candidates leads to suboptimal hires and team performance
- Business Delays: Extended hiring cycles postpone critical projects and initiatives
- Higher Costs: Inefficient processes and prolonged vacancies increase recruitment costs
Our Solution
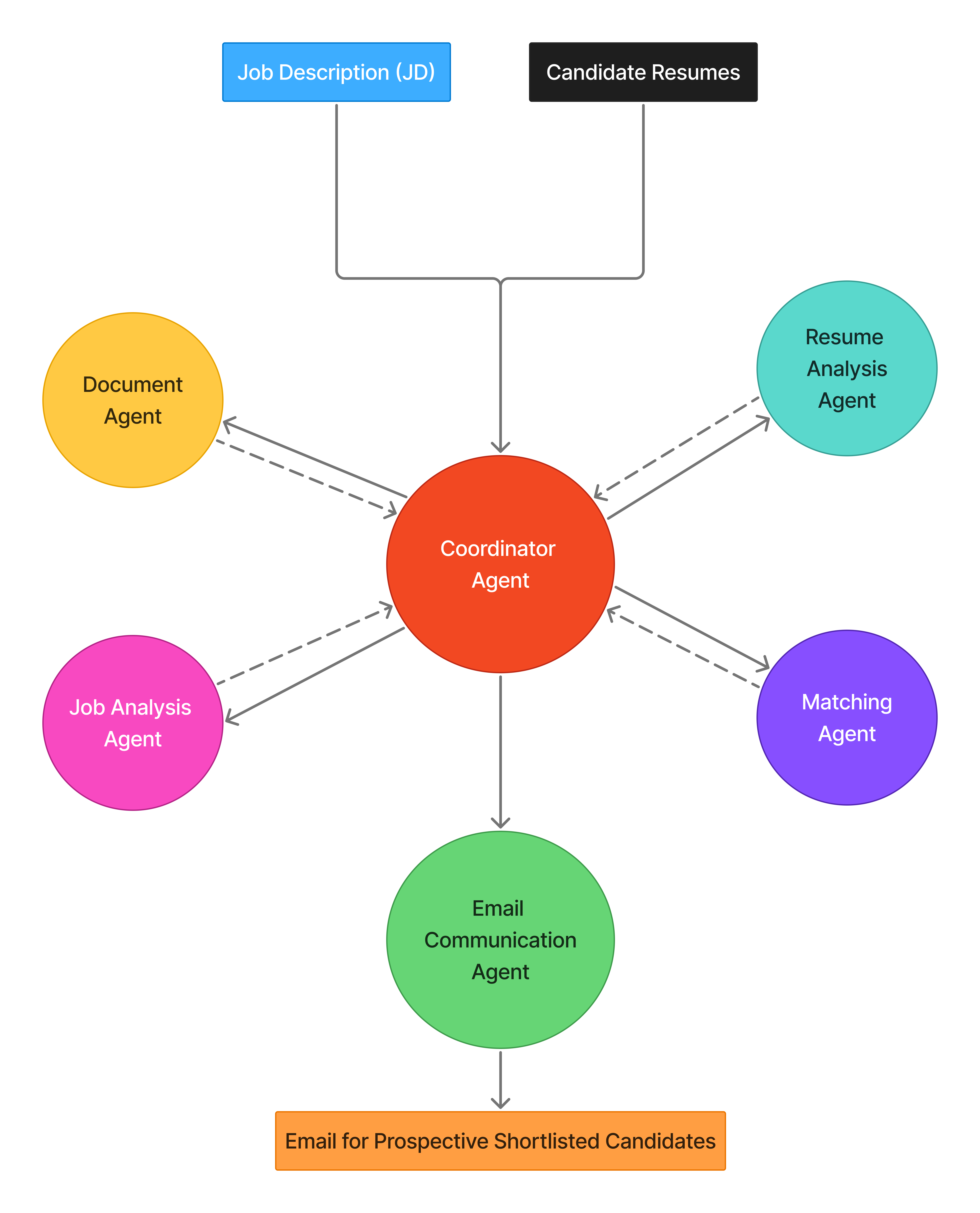
The Multi Agent Workflow For Recruitment addresses these challenges through a coordinated system of specialized AI agents:
-
DocumentAgent: Intelligently extracts and processes text from resumes and job descriptions using advanced Mistral's OCR
-
JobAnalysisAgent: Analyzes job descriptions to identify required skills, experience, and qualifications
-
ResumeAnalysisAgent: Parses resumes to create structured candidate profiles with key capabilities
-
MatchingAgent: Evaluates candidates against job requirements with nuanced understanding beyond keyword matching
-
EmailCommunicationAgent: Generates personalized email communications and schedules interviews with qualified candidates
-
CoordinatorAgent: Orchestrates the entire workflow between agents for seamless operation.
The solution uses Mistral LLM for language understanding, structured output mechanisms for consistent data extraction, and Mistral OCR for document parsing.
Example: Data Scientist Hiring
To illustrate how the Multi Agent Workflow For Recruitment operates in practice, consider a realistic example:
HireFive needs to hire a Senior Data Scientist with machine learning expertise. The job description specifies requirements including 3+ years of experience, proficiency in Python and deep learning frameworks, and a Master's degree in a quantitative field. From a pool of candidate resumes, the workflow automatically:
- Extracts structured requirements from the job description, identifying critical skills
- Parses all the resumes, creating standardized profiles with skills, experience, and education
- Evaluates each candidate, assigning scores like "Technical Skills: 32/40" and "Experience: 25/30"
- Identifies candidates scoring above the 70-point threshold
- Automatically sends personalized interview invitations with scheduling links to these candidates
The entire process completes in minutes, providing HireFive's hiring manager with a ranked list of qualified candidates while eliminating hours of manual resume screening.
Solution Architecture
Installation
!pip install mistralaiImports
import os
import time
import json
import requests
from typing import List, Optional, Dict, Any
from pydantic import BaseModel, Field
from mistralai import Mistral
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipartSetup API Keys
os.environ['MISTRAL_API_KEY'] = "YOUR MISTRALAI API KEY" # Get it from https://console.mistral.ai/api-keysInitialize Mistral API Client
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])Download Data
Here, we download the necessary data for the demonstration.
- Job Descrition.
- Candidate Resumes.
Helper functions to download Job description and candidate resumes
def download_job_description(url, output_path = "job_description.pdf"):
"""
Download job description from a given URL.
"""
response = requests.get(url)
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Downloaded {output_path}")
def download_resumes(url, local_dir="resumes"):
"""
Download resumes from the given URL.
"""
response = requests.get(url)
if response.status_code != 200:
print("Failed to retrieve folder contents:", response.text)
return
data = response.json()
os.makedirs(local_dir, exist_ok=True)
print(f"{len(data)} files available for download:")
for file in data:
file_name = file["name"]
download_url = file["download_url"]
r = requests.get(download_url)
with open(os.path.join(local_dir, file_name), "wb") as f:
f.write(r.content)
print(f"Downloaded {file_name}")Download Job Description
url = "https://raw.githubusercontent.com/mistralai/cookbook/main/mistral/agents/non_framework/recruitment_agent/job_description.pdf"
output_path = "job_description.pdf"
download_job_description(url, output_path)Download Candidate Resumes
download_resumes(
url = "https://api.github.com/repos/mistralai/cookbook/contents/mistral/agents/non_framework/recruitment_agent/resumes",
local_dir="resumes"
)Define Pydantic Models
Pydantic models provide structured data validation between agents, ensuring consistent formats for candidate profiles, job requirements, and evaluation scores while enabling seamless integration with Mistral LLM's parsing capabilities. Following are the different pydantic models we use for
-
Skill: Represents a candidate's technical or soft skill with its proficiency level and years of experience.
-
Education: Captures educational qualifications including degree, field of study, institution, and performance metrics.
-
Experience: Tracks professional experience with role details, duration, utilized skills, and key accomplishments.
-
ContactDetails: Stores candidate contact information including name, email, and optional communication channels.
-
JobRequirements: Defines position requirements including mandatory and preferred skills, experience level, and educational qualifications.
-
CandidateProfile: Consolidates a candidate's complete professional profile including contact details, skills, education, and work history.
-
SkillMatch: Evaluates individual skill alignment between job requirements and candidate capabilities with confidence scores.
-
CandidateScore: Provides comprehensive scoring across key evaluation areas with total score calculation and identified strengths/gaps.
-
CandidateResult: Connects file information with extracted candidate data and evaluation scores for final ranking and selection.
Pydantic Models for structured extraction.
class Skill(BaseModel):
name: str = Field(description="Name of the skill or technology")
level: Optional[str] = Field(description="Proficiency level (beginner, intermediate, advanced)")
years: Optional[float] = Field(description="Years of experience with this skill")
class Education(BaseModel):
degree: str = Field(description="Type of degree or certification obtained")
field: str = Field(description="Field of study or specialization")
institution: str = Field(description="Name of educational institution")
year_completed: Optional[int] = Field(description="Year when degree was completed")
gpa: Optional[float] = Field(description="Grade Point Average, typically on 4.0 scale")
class Experience(BaseModel):
title: str = Field(description="Job title or position held")
company: str = Field(description="Name of employer or organization")
duration_years: float = Field(description="Duration of employment in years")
skills_used: List[str] = Field(description="Skills utilized in this role")
achievements: List[str] = Field(description="Key accomplishments or responsibilities")
relevance_score: Optional[float] = Field(description="Relevance to current job opening (0-10 scale)")
class ContactDetails(BaseModel):
name: str = Field(description="Full name of the candidate")
email: str = Field(description="Primary email address for contact")
phone: Optional[str] = Field(description="Phone number with country code if applicable")
location: Optional[str] = Field(description="Current city and country/state")
linkedin: Optional[str] = Field(description="LinkedIn profile URL")
website: Optional[str] = Field(description="Personal or portfolio website URL")
class JobRequirements(BaseModel):
required_skills: List[Skill] = Field(description="Skills that are mandatory for the position")
preferred_skills: List[Skill] = Field(description="Skills that are desired but not required")
min_experience_years: float = Field(description="Minimum years of experience required")
required_education: List[Education] = Field(description="Mandatory educational qualifications")
preferred_domains: List[str] = Field(description="Industry domains or sectors preferred for experience")
class CandidateProfile(BaseModel):
contact_details: ContactDetails = Field(description="Candidate's personal and contact information")
skills: List[Skill] = Field(description="Technical and soft skills possessed by the candidate")
education: List[Education] = Field(description="Educational background and qualifications")
experience: List[Experience] = Field(description="Professional work history and experience")
class SkillMatch(BaseModel):
skill_name: str = Field(description="Name of the skill being evaluated")
present: bool = Field(description="Whether the candidate possesses this skill")
match_level: float = Field(description="How well the candidate's skill matches the requirement (0-10 scale)")
confidence: float = Field(description="Confidence in the skill evaluation (0-1 scale)")
notes: str = Field(description="Additional context about the skill match assessment")
class CandidateScore(BaseModel):
technical_skills_score: float = Field(description="Assessment of technical capabilities (0-40 points)")
experience_score: float = Field(description="Evaluation of relevant work experience (0-30 points)")
education_score: float = Field(description="Rating of educational qualifications (0-15 points)")
additional_score: float = Field(description="Score for other relevant factors (0-15 points)")
total_score: float = Field(description="Aggregate candidate evaluation score (0-100)")
key_strengths: List[str] = Field(description="Primary candidate advantages for this role")
key_gaps: List[str] = Field(description="Areas where the candidate lacks desired qualifications")
confidence: float = Field(description="Overall confidence in the evaluation accuracy (0-1 scale)")
notes: str = Field(description="Supplementary observations about the candidate fit")
class CandidateResult(BaseModel):
file_name: str = Field(description="Name of the source resume file")
contact_details: ContactDetails = Field(description="Candidate's contact information")
candidate_profile: CandidateProfile = Field(description="Complete extracted candidate profile")
score: CandidateScore = Field(description="Detailed evaluation scores and assessment")Base Agent Class
The Agent class serves as the foundation for all specialized agents, providing a standardized interface for processing and communicating between agents in the recruitment workflow.
Each agent implements the common process() method while inheriting identity management and communication capabilities.
class Agent:
def __init__(self, name: str, client: Mistral):
self.name = name
self.client = client
def process(self, message):
"""Base process method - to be implemented by child classes"""
raise NotImplementedError("Subclasses must implement process method")
def communicate(self, recipient_agent, message):
"""Send message to another agent"""
return recipient_agent.process(message)DocumentAgent: Handles document extraction and OCR
The DocumentAgent handles document processing by extracting structured text from various files using Mistral's OCR capabilities. It transforms complex resume PDFs and job descriptions into text, serving as the initial data gateway for the entire recruitment workflow.
class DocumentAgent(Agent):
def __init__(self, client: Mistral):
super().__init__("DocumentAgent", client)
def process(self, file_info):
"""Process document extraction request"""
file_path, file_name = file_info
return self.extract_text_from_file(file_path, file_name)
def extract_text_from_file(self, file_path: str, file_name: str) -> str:
"""Extract text from a file using Mistral OCR"""
try:
# Upload the file
uploaded_file = self.client.files.upload(
file={
"file_name": file_name,
"content": open(file_path, "rb"),
},
purpose="ocr"
)
# Get signed URL
signed_url = self.client.files.get_signed_url(file_id=uploaded_file.id)
# Process with OCR
ocr_response = self.client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": signed_url.url,
}
)
# Extract and return the text
extracted_text = ""
for page in ocr_response.pages:
extracted_text += page.markdown + "\n\n"
return extracted_text
except Exception as e:
print(f"Error extracting text from {file_name}: {str(e)}")
return ""JobAnalysisAgent: Handles job requirement extraction and analysis
The JobAnalysisAgent extracts structured job requirements from plain text job descriptions using Mistral LLM. It transforms unstructured job postings into organized data models capturing required skills, experience levels, and educational qualifications needed for candidate matching.
class JobAnalysisAgent(Agent):
def __init__(self, client: Mistral):
super().__init__("JobAnalysisAgent", client)
def process(self, jd_text):
"""Process job description text"""
return self.extract_job_requirements(jd_text)
def extract_job_requirements(self, jd_text: str) -> JobRequirements:
"""Extract structured job requirements from a job description"""
prompt = f"""
Extract the key job requirements from the following job description.
Focus on required skills, preferred skills, experience requirements, and education requirements.
Job Description:
{jd_text}
"""
response = self.client.chat.parse(
model="mistral-small-latest",
messages=[
{"role": "system", "content": "Extract structured job requirements from the job description."},
{"role": "user", "content": prompt}
],
response_format=JobRequirements,
temperature=0
)
return json.loads(response.choices[0].message.content)ResumeAnalysisAgent: Handles resume parsing and profile extraction
The ResumeAnalysisAgent transforms raw resume text into structured candidate profiles using Mistral LLM's parsing capabilities. It extracts and organizes key information including contact details, skills, education history, and professional experience into standardized data structures for consistent evaluation.
class ResumeAnalysisAgent(Agent):
def __init__(self, client: Mistral):
super().__init__("ResumeAnalysisAgent", client)
def process(self, resume_text):
"""Process resume text"""
return self.extract_candidate_profile(resume_text)
def extract_candidate_profile(self, resume_text: str) -> CandidateProfile:
"""Extract structured candidate information from resume text"""
prompt = f"""
Extract the candidate's contact details, skills, education, and experience from the following resume.
Be thorough and include all relevant information.
Resume:
{resume_text}
"""
response = self.client.chat.parse(
model="mistral-small-latest",
messages=[
{"role": "system", "content": "Extract structured candidate information from the resume."},
{"role": "user", "content": prompt}
],
response_format=CandidateProfile,
temperature=0
)
return json.loads(response.choices[0].message.content)MatchingAgent: Evaluates candidate fit against job requirements
The MatchingAgent evaluates candidate profiles against job requirements to generate comprehensive scoring across technical skills, experience, education and additional qualifications. It employs Mistral LLM to assess the quality and relevance of candidate attributes beyond simple keyword matching, producing a detailed evaluation with confidence metrics and identified strengths and gaps.
class MatchingAgent(Agent):
def __init__(self, client: Mistral):
super().__init__("MatchingAgent", client)
def process(self, data):
"""Process job requirements and candidate profile to generate score"""
job_requirements, candidate_profile, resume_text = data
return self.evaluate_candidate(job_requirements, candidate_profile, resume_text)
def evaluate_candidate(self, job_requirements: JobRequirements, candidate_profile: CandidateProfile, resume_text: str) -> CandidateScore:
"""Evaluate how well a candidate matches the job requirements"""
# Convert to JSON for inclusion in the prompt
job_req_json = json.dumps(job_requirements, indent=2)
candidate_json = json.dumps(candidate_profile, indent=2)
prompt = f"""
Evaluate how well the candidate matches the job requirements.
Job Requirements:
{job_req_json}
Candidate Profile:
{candidate_json}
Provide a detailed scoring breakdown, highlighting strengths and gaps.
Assess the quality and relevance of the candidate's experience, not just keyword matches.
Include confidence levels for your assessment.
Technical skills should be scored out of 40 points.
Experience should be scored out of 30 points.
Education should be scored out of 15 points.
Additional qualifications should be scored out of 15 points.
The total score should be out of 100 points.
"""
response = self.client.chat.parse(
model="mistral-small-latest",
messages=[
{"role": "system", "content": "Evaluate the candidate's match to the job requirements with detailed scoring."},
{"role": "user", "content": prompt}
],
response_format=CandidateScore,
temperature=0.2 # Slight randomness for nuanced evaluation
)
return json.loads(response.choices[0].message.content)EmailCommunicationAgent: Handles email generation and sending
The EmailCommunicationAgent generates personalized email communications to candidates and sends them through SMTP integration. It crafts contextually relevant messages based on candidate qualifications and scheduling information, managing the critical final step of candidate engagement in the recruitment workflow.
class EmailCommunicationAgent(Agent):
def __init__(self, client: Mistral, sender_email: str, app_password: str):
super().__init__("EmailCommunicationAgent", client)
self.sender_email = sender_email
self.app_password = app_password
def process(self, data):
"""Process email sending request"""
candidate, calendly_link, subject = data
return self.send_interview_invitation(candidate, calendly_link, subject)
def send_interview_invitation(self, candidate, calendly_link: str, subject: str):
"""Generate and send personalized email to candidate"""
name = candidate["contact_details"]['name']
email = candidate["contact_details"]['email']
# Create email HTML content
html_content = f"""\
<html>
<body>
<p>Hello {name},</p>
<p>I'm the Hiring Manager from HireFive. Thank you for applying for the Data Scientist position at our company.</p>
<p>We were impressed with your background and would like to schedule an initial screening call to discuss your experience and interest in the role.</p>
<p>Please select a suitable time slot using our <a href="{calendly_link}">Calendly link</a>.</p>
<p>Looking forward to speaking with you soon.</p>
<p>Best regards,<br>
Hiring Manager<br>
HireFive</p>
</body>
</html>
"""
if self.app_password:
try:
self.send_email(email, subject, html_content)
return f"Email sent to {name} at {email}"
except Exception as e:
return f"Failed to send email to {name} ({email}): {str(e)}"
else:
return f"Would send email to {name} at {email} - Email subject: {subject}"
def send_email(self, receiver_email, subject, html_content):
"""Send an email using Gmail SMTP"""
# Create message container
message = MIMEMultipart('alternative')
message['From'] = self.sender_email
message['To'] = receiver_email
message['Subject'] = subject
# Attach HTML part
message.attach(MIMEText(html_content, 'html'))
try:
# Create SMTP session
server = smtplib.SMTP('smtp.gmail.com', 587)
server.starttls() # Enable security
# Login with Gmail account and app password
server.login(self.sender_email, self.app_password)
# Send email
text = message.as_string()
server.sendmail(self.sender_email, receiver_email, text)
finally:
server.quit() # Close the connectionCoordinatorAgent: Manages the workflow and coordinates between agents
The CoordinatorAgent orchestrates the entire recruitment workflow by managing communication and data flow between all specialized agents. It initializes the process with job descriptions, distributes resumes, collects evaluation results, applies threshold-based filtering, and triggers candidate communications, serving as the central intelligence that ensures the seamless execution of the multi-agent recruitment system.
class CoordinatorAgent(Agent):
def __init__(self, client: Mistral):
super().__init__("CoordinatorAgent", client)
self.document_agent = DocumentAgent(client)
self.job_analysis_agent = JobAnalysisAgent(client)
self.resume_analysis_agent = ResumeAnalysisAgent(client)
self.matching_agent = MatchingAgent(client)
self.email_communication_agent = None # Will be initialized later with email credentials
def set_email_communication_agent(self, sender_email: str, app_password: str):
"""Initialize communication agent with email credentials"""
self.email_communication_agent = EmailCommunicationAgent(self.client, sender_email, app_password)
def process_hiring_workflow(self, jd_file_path: str, resume_dir: str, output_path: str,
threshold_score: float, calendly_link: str, email_subject: str):
"""
Coordinate the entire hiring workflow from document processing to interview scheduling
"""
results = []
# Process job description
print(f"🤖 DocumentAgent extracting text from job description...")
jd_text = self.document_agent.process((jd_file_path, os.path.basename(jd_file_path)))
if not jd_text:
print("❌ Failed to extract text from job description. Aborting.")
return results
# Extract job requirements
print(f"🤖 JobAnalysisAgent analyzing job description...")
job_requirements = self.job_analysis_agent.process(jd_text)
time.sleep(10)
# Process each resume in the directory
resume_files = [f for f in os.listdir(resume_dir) if os.path.isfile(os.path.join(resume_dir, f))]
for filename in resume_files[:5]:
file_path = os.path.join(resume_dir, filename)
print(f"\n🤖 DocumentAgent processing resume: {filename}")
# Extract text from resume
resume_text = self.document_agent.process((file_path, filename))
time.sleep(10)
if resume_text:
# Extract candidate profile
print(f"🤖 ResumeAnalysisAgent extracting candidate profile...")
candidate_profile = self.resume_analysis_agent.process(resume_text)
# Evaluate candidate match
print(f"🤖 MatchingAgent evaluating candidate {candidate_profile['contact_details']['name']}...")
score = self.matching_agent.process((job_requirements, candidate_profile, resume_text))
# Create result object
result = {
"file_name": filename,
"contact_details": candidate_profile["contact_details"],
"candidate_profile": candidate_profile,
"score": score
}
results.append(result)
# Add a small delay to avoid rate limits
time.sleep(10)
else:
print(f"❌ DocumentAgent failed to extract text from {filename}. Skipping this resume.")
# Sort results by total score
results.sort(key=lambda x: x["score"]['total_score'], reverse=True)
# Save results to file
with open(output_path, 'w') as f:
json.dump([result for result in results], f, indent=2)
print(f"\n🤖 CoordinatorAgent saved results to {output_path}")
# Print summary of results
print("\n===== CANDIDATE RANKING =====")
for i, result in enumerate(results, 1):
name = result["contact_details"]['name']
score = result["score"]['total_score']
print(f"{i}. {name}: {score}/100")
# Send interview invitations to candidates above threshold
if self.email_communication_agent:
selected_candidates = [r for r in results if r["score"]['total_score'] >= threshold_score]
print(f"\n🤖 EmailCommunicationAgent preparing to send interview invitations to {len(selected_candidates)} candidates who scored {threshold_score}+ out of 100...\n")
for candidate in selected_candidates:
response = self.email_communication_agent.process((candidate, calendly_link, email_subject))
time.sleep(1)
return resultsRun the workflow
To run the Multi Agent Workflow For Recruitment, you simply need to:
- Configure file paths for the job description, resume directory, and output results
- Set up email credentials and Calendly scheduling link
- Initialize the CoordinatorAgent with your Mistral client
- Configure the EmailCommunicationAgent with sender credentials
- Execute the workflow with your desired threshold score
Define paths
jd_file_path = "job_description.pdf"
resume_dir = "resumes/"
output_path = "candidate_results.json"Gmail App Password Setup
To use the email functionality in the Multi Agent Workflow For Recruitment with Gmail, you'll need to create an app password:
-
Enable 2-Step Verification on your Google Account:
- Go to your Google Account → Security
- Under "Signing in to Google," select 2-Step Verification → Get started
-
Generate an App Password:
- Go to your Google Account → Security
- Under "Signing in to Google," select App passwords
- Select "Mail" as the app and "Other" as the device (name it "Recruitment Workflow")
- Click "Generate"
- Google will display a 16-character password (four groups of four characters)
-
Use this app password in your workflow configuration:
sender_email = "your.email@gmail.com" app_password = "abcd efgh ijkl mnop" # Your generated app password
This app password bypasses 2FA and allows the workflow to send emails through your Gmail account securely without storing your actual Google password in the code.
sender_email = "<Your EmailID>"
app_password = "<Your generated app password>"
calendly_link = "<Your Calendly Link>"
email_subject = "HireFive: Next Steps for Your Data Scientist Application"Initialize coordinator agent
coordinator = CoordinatorAgent(client)Set up communication agent with email credentials
coordinator.set_communication_agent(sender_email, app_password)Execute hiring workflow
Note: We have considered 5 candidate resumes for simplicity's sake.
threshold_score = 65 # Only send to candidates with 65+ overall score
results = coordinator.process_hiring_workflow(
jd_file_path=jd_file_path,
resume_dir=resume_dir,
output_path=output_path,
threshold_score=threshold_score,
calendly_link=calendly_link,
email_subject=email_subject
)You can check each of the candidates extracted results.
results